

Notation
1. 서 론
2. ACI 408R-03 개요 및 부착강도 예측 체계
2.1 ACI 408R-03 배경
2.2 부착 매커니즘과 ACI 408의 기본 정의
2.3 설계식(design provisions)으로의 변환: 신뢰도 기반 𝜙 적용과 ACI 318과의 관계
2.4 ACI 408 데이터베이스와 부착응력 산정(모멘트-곡률 기반)의 의미
2.5 요약: ACI 408을 AI 대체 모델의 기준선(baseline)으로 쓰는 이유
3. AI 기반 부착강도 대체 모델 개발 및 알고리즘 비교
3.1 연구 목적과 전체 절차 개요
3.2 데이터 구성: ACI 408 실험 데이터와 목표 출력 정의
3.3 학습/검증 데이터 분할 및 교차검증 전략과 하이퍼파라미터 최적화(Optuna 적용)
3.4 비교 대상 알고리즘(6종)
3.5 SHAP 기반 해석가능성 분석 및 파일럿 점검
4. AI 기반 부착강도 대체 모델 결과 및 토의
4.1 결과 제시 원칙과 평가 지표
4.2 기준선(ACI 408R-03) 대비 AI 모델의 예측 특성
4.3 알고리즘별 성능 비교 결과
4.4 SHAP 기반 특징변수 영향 분석
4.5 적용 범위 및 한계
5. 결 론
Notation
Ab 철근 단면적
Atr 횡보강 단면적
b 시험체(부재) 폭
c 콘크리트 커버길이
cbcsi, cso에 수직한 방향의 하부 커버길이
cmin, cmax 피복 및 간격 관련 변수
csi 철근간 순간격의 1/2
csocsi와 같은 평면에서의 측면 피복
d 보의 유효깊이(effective depth)
db 철근 공칭 직경
dtr 전단철근/띠철근 간격 및 배근 형상 등에 따른 보정 변수
f‘c 콘크리트 압축강도
fy 철근 항복강도
fyt 횡보강 항복강도
fs 파괴 시 철근 응력
h 단면 전체 높이(전체 깊이)
jd 모멘트–철근력 환산에서 사용되는 내부 레버암
Ktr 횡보강 지수
ld 정착 길이
ls 최소 겹칩 길이
M1,M2 두 단면에서의 휨모멘트
N 이음/정착 길이 구간 내 스트럽 개수
n 전단철근/띠철근 배근 형상 등에 따른 보정 변수 (겹칩 및 부착 철근 개수)
Position 철근 배치 위치를 나타내는 데이터베이스 코드
Rr 상대 리브 면적. 무차원 지표로 정의(리브 투영면적을 철근 둘레 및 리브 간격으로 정규화)
Tb ACI 408 예측 틀에서 Abfs와 함께 언급되는 총 전달력 표기
Texp 실험 목표값(부착파괴 시 철근이 전달하는 총 힘)
T1,T2 두 단면에서의 철근 인장력
U 단위 길이당 부착력
u 평균 부착응력
ΔT 두 균열 단면 사이 철근 인장력 변화량
Σo 철근 둘레(둘레의 합)로 제시
1. 서 론
최근 산업시설·도심 인프라에서도 우발적 폭발, 테러에 의한 폭발·충격, 그리고 연쇄 붕괴와 같은 극한 하중 시나리오를 고려한 방호(보호)설계의 필요성이 커지고 있다. 방호설계의 핵심 목표는 단순히 부재의 강도 확보를 넘어, 국부 손상 이후에도 구조체가 하중 경로를 유지하며 인명·자산 피해를 최소화하도록 하는 것이다. 이에 따라 설계 단계에서부터 극한 하중에 대한 구조응답을 정확하게 예측하는 것이 요구되며, 특히 철근콘크리트(RC) 구조물의 경우 고변형률 조건에서의 비선형 거동을 적절히 반영해야 한다. Lee and Kwak(2018)은 폭발·충격 하중에서 RC 부재 응답을 정확히 예측하기 위해서는 재료의 고변형률 거동뿐 아니라, 구조 저항능력에 지배적으로 영향을 주는 부착–미끄럼 비선형을 함께 고려해야 함을 명확히 언급한다.
RC 구조의 복합거동은 철근–콘크리트 사이의 부착을 통해 유지되며, 부착은 균열 이후에도 철근력이 콘크리트로 전달되고 부재가 목표 성능(강도·연성·에너지 흡수)을 발현하는 데 필수적이다. 부착이 충분하지 않으면, 철근이 설계된 응력 수준까지 “정착”되지 못하여 철근 항복 이전의 조기 미끄럼/뽑힘 또는 겹침이음부의 취성 파괴로 이어질 수 있고, 이는 방호설계에서 의도하는 연성 거동 및 연속성 확보를 저해한다. 실제로 방호 설계 지침들은 이러한 취약부(정착/이음/연결)의 중요성을 전제로 상세를 강화한다. 요컨대, 방호설계의 관점에서 부착강도 예측은 단순 재료특성의 문제가 아니라 연속 하중전달 경로와 변형능력을 좌우하는 구조 성능의 핵심 입력값이다.
이러한 배경에서, 부착강도 및 정착/이음 성능을 설계식으로 예측하기 위한 대표적 근거 문헌 중 하나가 ACI 408R-03(ACI Committee 408, 2003)이다. ACI 408R-03은 직선 이형철근의 인장 정착·이음 거동을 다루며, 다양한 변수(콘크리트 강도, 피복/간격, 철근 직경, 횡보강 등)를 포함하는 식과 설계 제안을 제시하고, 광범위한 실험 데이터베이스를 이용해 여러 설계식의 적합성과 안전성을 비교·검토한다.
그러나 기존 코드 기반 설계식은 실무 적용성 측면에서 장점이 크지만, 다음과 같은 한계를 구조적으로 내포한다. 첫째, 개발길이·겹침이음 예측식은 역사적으로 실험 데이터에 대한 회귀를 통해 정립되어 왔으며, 데이터 범위를 벗어난 조건에서의 적용성은 종종 논쟁의 대상이 된다. Canbay and Frosch(2006)는 겹침이음 강도 평가식이 주로 시험결과의 비선형 회귀분석에 근거하며, 데이터 영역 밖 적용성에 대한 의문이 지속된다고 언급한다. 둘째, 예측 정확도를 높이기 위해 변수를 추가하면 식이 복잡해져 설계 활용성이 급격히 떨어진다. 동일 논문은 최근 연구들이 ACI 318보다 많은 변수를 포함해 정확도를 높이려 했지만, 변수가 늘어날수록 서술식이 복잡하고 번거로워 설계 적용에 불리해진다고 지적한다. 셋째, 부착은 균열, 구속, 철근 형상(리브 형상), 응력장등 다수 요인의 비선형 결합 문제이며, 특정 함수형을 전제로 한 폐형식(closed-form) 모델로는 상호작용을 충분히 포착하기 어렵다. 실제로 최근 리뷰 연구에서도 부착거동의 복잡성과 시험법(빔시험 vs 풀아웃 시험) 차이에 따른 응력장 영향이 강조되며, 빔시험이 실제 응력장을 더 잘 반영하므로 권장된다는 점이 정리되어 있다.
이러한 한계를 보완하기 위한 대안으로 인공지능/기계학습(ML) 기반 데이터 구동형 예측 모델이 구조공학 분야에서 빠르게 확산되고 있다. ML은 (i) 다변수–비선형 관계를 함수형 가정 없이 학습할 수 있고, (ii) 상호작용과 임계 현상을 데이터로부터 포착할 수 있으며, (iii) 데이터가 추가될수록 지속적으로 갱신/개선될 수 있다. 또한 최근 연구들은 부착강도 예측에 ML을 적용할 경우 경험식 대비 정확도 향상을 보고하고, SHAP(Shapley Additive Explanations) 등 해석가능 기법을 통해 영향 인자 기여도를 설명하려는 시도도 제시한다.
따라서 본 논문은 ACI 408 데이터베이스만을 활용하여, ACI 408R-03의 부착 예측식을 AI 모델로 대체(또는 보완) 할 수 있는 가능성을 체계적으로 검토하는 것을 목표로 한다. 구체적으로는 (1) ACI 408R-03의 예측 틀과 동일한 입력변수(예: 콘크리트 강도, 피복/간격, 철근 직경, 횡보강 등)를 기반으로 학습 데이터를 구성하고, (2) 교차검증을 통한 일반화 성능을 확보하며, (3) 코드식 대비 예측 정확도뿐 아니라 극한 하중 시나리오에서 요구되는 신뢰성 기반 의사결정에 기여하고자 한다. 또한 가능하다면 SHAP 등 해석가능 도구를 통해 모델이 특정 예측을 하는지 설명하여, 단순한 블랙박스가 아닌 설계 공학적 활용이 가능한 AI 기반 부착강도 예측 프레임워크를 제시한다. 이는 ACI 408 기반 데이터만으로도, 코드식의 형태를 유지하지 않더라도 더 높은 적합도를 갖는 예측기가 가능함을 시사한다.
2. ACI 408R-03 개요 및 부착강도 예측 체계
2.1 ACI 408R-03 배경
ACI 408R-03는 ACI Committee 408이 발간한 위원회 보고서로, 철근콘크리트 부재에서 직선 이형철근의 부착(bond)과 정착·이음 거동을 정리하고, 실험 데이터베이스에 근거한 예측식과 이를 설계식으로 전환하는 절차를 제시한다. ACI 408R-03는 부착강도 산정에서 관찰되는 큰 산포가 단순히 압축강도만의 문제가 아니라 콘크리트 파괴에너지 같은 재료 특성 등 통상 설계에서 직접 고려하지 않는 요인들로부터 상당 부분 기인함을 명시한다. 또한 지진, 충격, 폭발 등과 같은 동적 거동은 본 보고서의 범위에서 다루지 않는다고 밝힌다. 이 점은 ACI 408 기반 경험식의 장점과 한계를 동시에 규정하는 전제 조건이 된다.
2.2 부착 매커니즘과 ACI 408의 기본 정의
ACI 408R-03는 부착을 접착, 마찰, 리브에 의한 지압·쐐기작용이 결합된 힘 전달 현상으로 설명하고, 특히 이형철근에서는 리브에 의한 지압과 그로 인한 균열·쐐기작용이 핵심임을 강조한다. 리브 형상을 대표하는 지표로 상대 리브면적(relative rib area: Rr)을 소개하고, 이를 통해 철근 형상 차이가 부착거동에 미치는 영향을 정량화한다. 전통적으로 부착은 “부착응력” 개념으로 다루어져 왔지만, ACI 408R-03는 실제 부재에서 부착력이 철근 길이 방향으로 균일하지 않고(균열 위치, 콘크리트 분담 인장력 등 미지의 요인에 의해) 심지어 방향도 바뀔 수 있음을 설명한다. 그럼에도 설계의 목표는 부착파괴가 아닌 다른 연성 파괴 형태로 거동을 유도하는 것이므로, 설계에서는 편의적으로 등분포 부착을 가정하는 경우가 많았다고 정리한다.
ACI 408R-03의 기본 출발점은 단면력 변화에 따른 철근 인장력 변화이다. 예를 들어, 두 균열 단면 사이 철근 인장력 변화는 ΔT = T1 − T2 = M1/(jd1) − M2/(jd2)으로 미소 구간에서는 dT = (dM)/(jd)로 정리된다. 이때 단위 길이당 부착력 U를 dT/dl로 정의하면, 평균 부착응력 u는 U를 철근 둘레 Σo로 나눈 값으로 나타낼 수 있다. 다만, 보고서는 부착응력 u만을 정착길이 산정의 유일한 근거로 두는 것은 부적절하며 권장되지 않는다고 명시적으로 언급한다. 즉 ACI 408의 핵심은 응력(τ) 기반이라기보다 정착(또는 이음) 파괴 시 철근에 전달되는 총 부착력(총 전달력) 또는 철근력을 중심으로 모델을 구성한다는 점이다.
ACI 408R-03는 리브 형상이 부착 거동에 미치는 영향을 상대 리브면적 Rr로 정리한다. Rr은 철근의 단위 리브 간격에 대한 리브의 투영면적(축에 수직인 투영)을 철근 둘레와 리브 간격의 곱으로 정규화한 무차원 지표로 정의되며, 표준 이형철근의 경우 대체로 일정 범위의 값(예: 평균적인 수준의 Rr)을 갖는다고 설명한다. 실무적 관점에서 Rr은 철근 리브가 콘크리트를 얼마나 강하게 밀어 벌리는가(쐐기작용)를 간접적으로 나타내는 변수로서, 특히 구속이 충분할 때(횡보강 또는 큰 피복·간격) 리브 형상 차이가 더 강도 차이로 나타날 수 있음을 보고서는 배경적으로 설명한다.
2.3 설계식(design provisions)으로의 변환: 신뢰도 기반 𝜙 적용과 ACI 318과의 관계
ACI 408R-03 Chapter 4는 서술식(평균 거동)을 설계식(낮은 파괴확률)으로 전환하는 과정을 제시한다. 보고서는 위원회 권고 정착·이음 설계식이 Zuo and Darwin(2000)의 연구를 기반으로 하고, Chapter 3에서 데이터베이스로 업데이트된 식을 기반으로 설계형으로 정리되었다고 설명한다. 또한 신뢰도 기반의 𝜙(강도감소계수) 적용 논리를 함께 다룬다.
ACI 318의 대표적인 개발길이 표현은 Ktr(횡보강 지수)와 기하 변수(c + Ktr)/db를 포함하며, 여기서 Ktr = (Atr·fyt)/(1500 sn)로 주어진다. 보고서는 명목강도에서 fs = fy를 대입하여 ACI 318에서 사용하는 형태로 단순화되는 과정도 함께 설명한다. 외부 비교 연구에서도 ACI 318과 ACI 408R-03 권고식이 주요 비교 대상으로 다뤄진다. 예를 들어 Canbay and Frosch(2006)는 ACI 318-05의 개발·이음 규정이 Orangun et al.(1977)의 회귀 기반 부착식에 기초하며, ACI 408R-03는 Zuo and Darwin(2000)에 기반한 권고식을 제시한다고 정리한다.
2.4 ACI 408 데이터베이스와 부착응력 산정(모멘트-곡률 기반)의 의미
ACI 408R-03 Chapter 5는 ACI 408 데이터베이스를 소개한다. 보고서는 집계 시점 기준으로 “무도막 철근”에 대한 development 및 splice 시험 결과가 데이터베이스에 포함되어 있으며, 총 635개 시험의 결과가 포함된다고 밝힌다. 특히, 논문 작성 및 데이터 분석 관점에서 중요한 내용은 파괴 시 철근응력(예: fsc 혹은 fs)의 산정 방법이다. 보고서는 데이터베이스에서 철근응력을 단순히 항복으로 가정하지 않고, 모멘트-곡률 해석을 사용하여 파괴 시 철근응력을 계산했다고 명시한다. 또한 재료모델(콘크리트의 응력-변형률 관계, 철근의 탄성계수 및 항복강도 등) 가정과 관련된 처리도 설명한다.
즉, ACI 408의 Ab·fs(또는 Tb) 기반 예측식에서 fs는 실험체가 실제로 부착파괴에 도달했을 때 철근이 부담한 응력이며, 이는 단면 해석(모멘트-곡률)을 통해 추정되었기 때문에, 동일한 실험이라도 해석 가정(재료모델, 단면 유효깊이, 철근 배치 등)에 따라 fs 값이 달라질 여지가 있다. 이 지점은 사용자가 구축한 데이터셋에서 Results(Tb) = Ab × fs 형태를 실험값으로 사용할 때, 데이터 정합성과 단위계 검증이 매우 중요하다는 점을 의미한다. 특히, fs의 변수는 실험 결과의 값으로 기계학습 알고리즘 학습 시 반드시 제외되어야 할 변수임을 다시 한번 강조한다.
2.5 요약: ACI 408을 AI 대체 모델의 기준선(baseline)으로 쓰는 이유
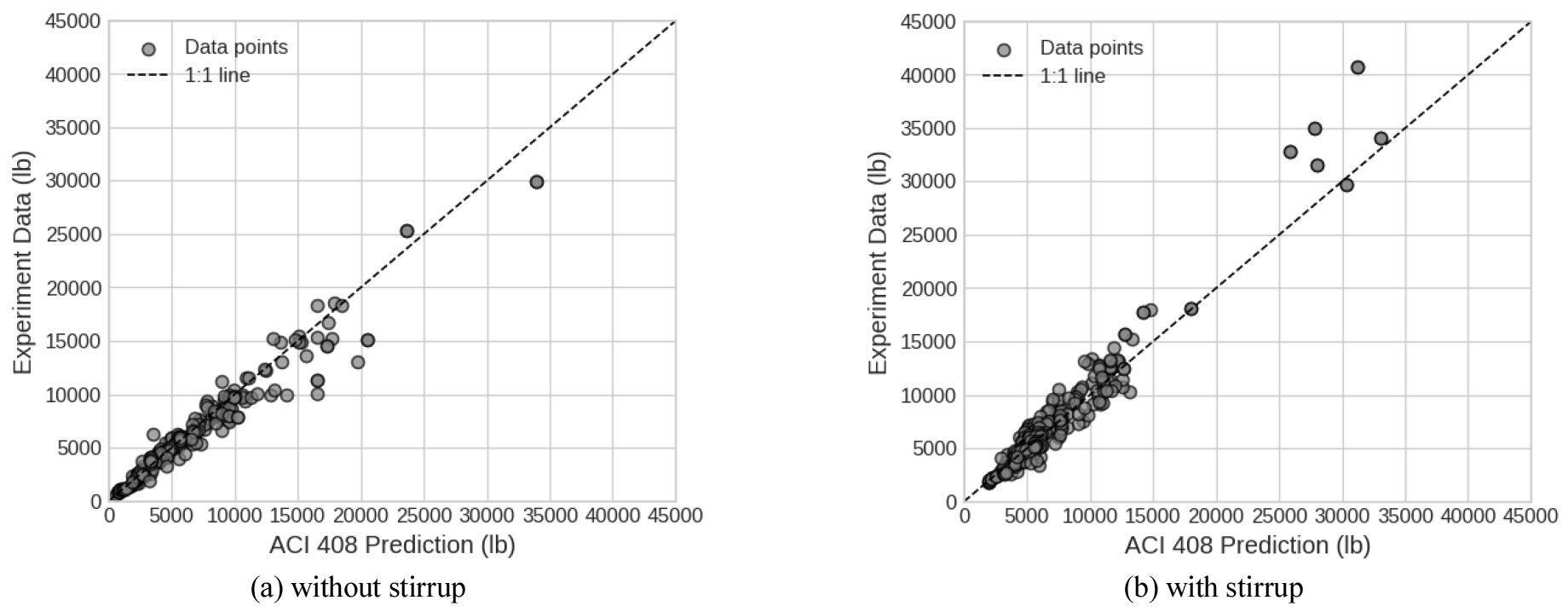
정리하면 ACI 408R-03는 (1) 부착 거동을 “부착응력 하나”로 단순화하기보다, (2) 기하(피복·간격), 재료강도, 리브 형상(Rr), 횡구속(N, Atr, sn, n) 등을 포함한 실험 기반의 총 전달력(Ab·fs) 예측 틀을 제공하고, (3) 서술식에서 설계식으로의 전환을 신뢰도 관점에서 체계화한다는 점에서, AI 기반 대체 모델 연구에서 매우 좋은 기준선이 된다. 동시에 보고서가 직접 언급하듯 산포의 원인(파괴에너지, 리브 형상, 시공·재료 편차 등)이 기존 설계 변수로 완전히 설명되지 않기 때문에, 동일 데이터로 ACI 408 예측치와 실험치를 비교하면 상당한 분산이 발생할 수 있다. ACI 408R-03 서술식 기반 예측치와 실험치의 관계는 Fig. 1에 제시하였다. 전단철근(횡보강) 유무에 따라 산포 양상이 달라지며, 특히 고전달력 구간에서 1:1선 주변의 편차가 확대되는 경향이 관찰된다. 이러한 산포는 ACI 408R-03이 전제하는 제한된 설계변수만으로는 부착 파괴의 비선형 상호작용을 완전히 설명하기 어려움을 시사하며, 데이터 기반 AI 모델의 보완 가능성을 뒷받침한다.
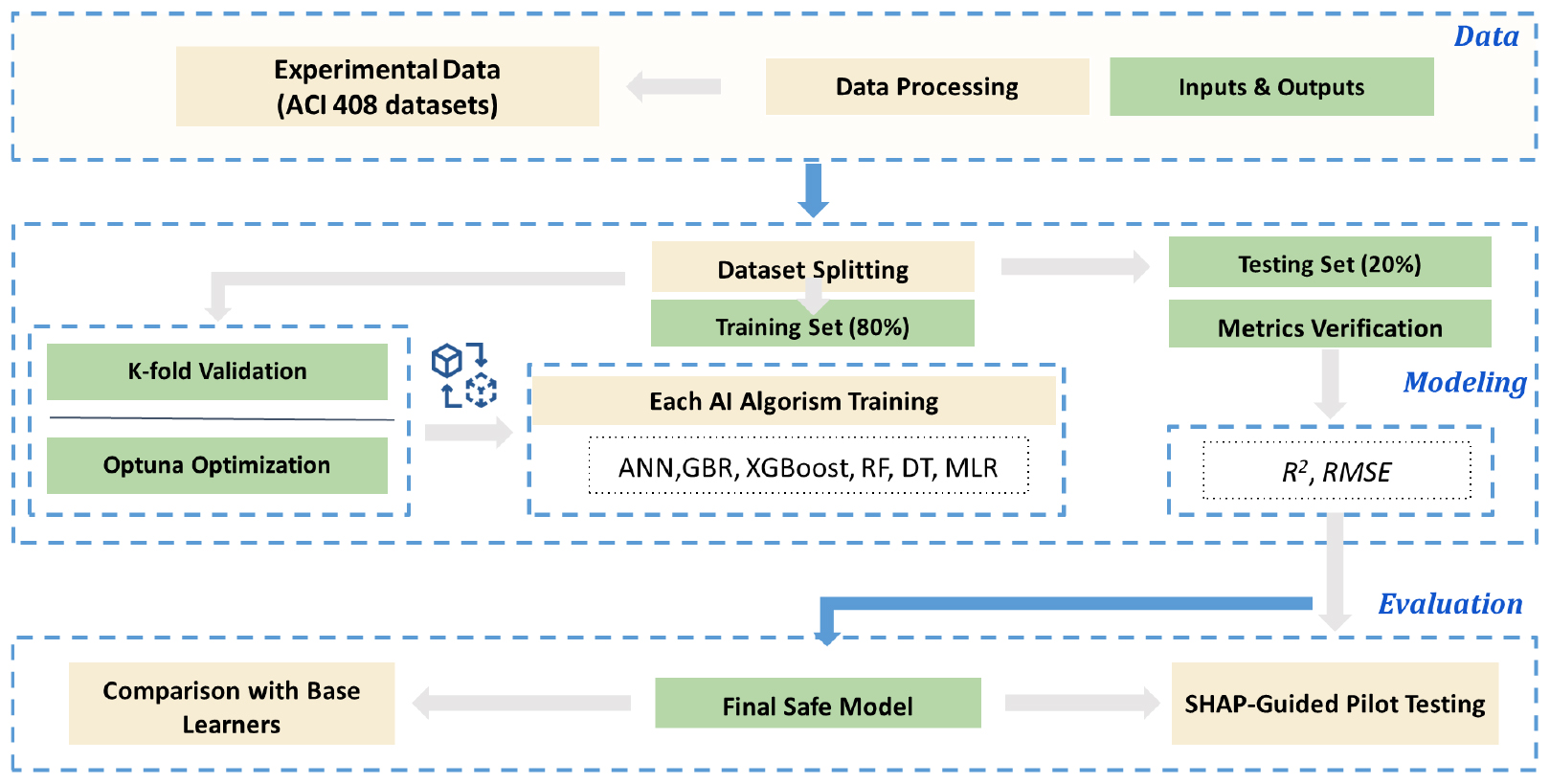
3. AI 기반 부착강도 대체 모델 개발 및 알고리즘 비교
3.1 연구 목적과 전체 절차 개요
본 장에서는 ACI 408R-03의 서술식(예: 횡보강 유무에 따라 구분되는 총 전달력 예측식)을 기준선으로 두고, 동일한 ACI 408 데이터베이스를 이용하여 부착강도(Results = Ab·fs)를 예측하는 인공지능(기계학습) 대체 모델을 구축한 절차를 설명한다. ACI 408R-03는 데이터베이스 기반으로 신뢰도, 안전성, 경제성을 개선하기 위한 서술식과 설계 절차를 제시하는 문헌이며, 본 연구의 AI 모델은 이러한 경험식의 형태를 유지하지 않고도 예측 정확도를 개선할 수 있는지 검토하는 데 목적이 있다.
Fig. 2는 본 연구의 전 과정을 요약한다. 즉, (1) ACI 408 데이터로부터 입력과 출력 변수를 구성하고, (2) 결측치 및 단위의 일관성을 확보하는 전처리를 수행한 다음, (3) 학습/시험 데이터 분할을 통해 일반화 성능을 독립적으로 검증한다. 이어서 (4) 학습 데이터에 대해 k-fold 교차검증을 수행하고, (5) Optuna(Akiba et al., 2019) 기반 하이퍼파라미터 최적화를 통해 각 알고리즘의 성능을 최대화하며, (6) 최종적으로 시험 데이터에서 성능지표를 산정하여 최적 알고리즘을 선정한다. 마지막으로 (7) SHAP 기반 해석 가능성 분석을 통해 모델이 어떤 변수를 근거로 예측하는지 점검하고, 물리적 일관성 관점에서 파일럿 검증을 수행한다.
3.2 데이터 구성: ACI 408 실험 데이터와 목표 출력 정의
본 연구는 ACI 408 데이터베이스(정착 및 겹침이음 실험자료)를 사용하였다. 데이터는 통상 US customary 단위계(예: 길이 inch, 응력 psi, 면적 in2)를 기반으로 정리되어 있으며, 본 연구에서도 ACI 408R-03 본문 식과 동일한 단위계를 유지하여 전처리 및 모델링을 수행하였다. 입력 변수는 ACI 408R-03의 부착(정착/이음) 예측식이 반영하는 주요 지배인자를 중심으로 구성하였다. 데이터베이스에 존재하는 대표 변수는 다음과 같다. 기하 및 정착 변수, 정착 길이(ld), 철근 직경(db), 피복 및 간격 관련(cmin, cmax), 재료 및 철근 변수, 콘크리트 압축강도(f’c), 철근 항복강도(fy), 구속 및 횡보강 변수, 횡보강 단면적(Atr), 횡보강 개수(N), 띠철근/전단철근 간격 및 배근 형상에 따른 보정 변수(데이터에 포함된 n, dtr 등), 철근 형상 변수, 상대 리브 면적, (Rr)이다. 이들 변수는 ACI 408R-03의 서술식 체계에서 부착파괴의 강도를 규정하는 핵심 인자로 취급된다. Table 1의 경우 훈련에 사용된 변수 및 범주와 관련된 통계적 정보를 제공해 준다.
Table 1
Descriptive statistics of the input and targe output in the ACI408 database used in this study
ACI 408R 서술식은 평균 부착응력 자체를 직접 예측하기보다, 정착/이음 구간에서 파괴 시 철근이 전달한 총 힘을 Ab·fs 형태로 표현하여 모델링한다. 본 연구에서도 실험 목표값을 동일한 의미의 총 전달력으로 정의하였다. 즉, 실험 목표값은 Tb = Ab·fs 이다. 여기서 Ab는 철근 단면적, fs는 파괴 시 철근응력이며, 곱 Ab·fs는 힘 단위에 해당한다.
3.3 학습/검증 데이터 분할 및 교차검증 전략과 하이퍼파라미터 최적화(Optuna 적용)
모델의 일반화 성능을 독립적으로 평가하기 위해 전체 데이터를 학습용 80%, 시험용 20%로 분할하였다. 이는 train_test_split 절차로 구현할 수 있으며, 랜덤 시드를 고정하여 재현성을 확보하였다. 학습 데이터 내부에서 모델 성능을 안정적으로 추정하고 과적합을 억제하기 위해 k-fold 교차검증을 적용하였다. k-fold는 전체 학습 데이터를 k개의 fold로 나누고, k-1개 fold로 학습한 뒤 나머지 1개 fold로 검증하는 과정을 k회 반복하여 평균 성능을 산정한다. 이 절차는 K-fold 교차검증기로 구현 가능하다. 본 연구에서는 5-fold 교차검증 성능을 하이퍼파라미터 탐색의 목적함수로 사용하여, 단일 분할에 의존한 우연적 성능 편차를 최소화하였다.
각 알고리즘은 모델 구조와 규제항, 학습률 등 하이퍼파라미터에 따라 성능 편차가 크게 발생한다. 따라서 본 연구에서는 Optuna를 사용해 하이퍼파라미터 탐색을 자동화하였다. Optuna는 define-by-run 방식으로 탐색공간을 동적으로 구성할 수 있고, pruning을 통해 성능이 낮은 trial을 조기 중단하여 계산 효율을 높이는 것이 특징이다. 목적함수는 교차검증 기반의 오차(RMSE)로 정의하였다. Table 2은 각 알고리즘별 하이퍼파라미터 탐색에 적용된 파라미터이다.
Table 2
Tuning parameters for each algorithms
3.4 비교 대상 알고리즘(6종)
본 연구는 부착강도(총 전달력) 예측을 회귀 문제로 정의하고, 6개 기계학습 알고리즘(ANN, RF, GBR, XGBoost, DT, MLR)을 비교하였다. 알고리즘 선정 기준은 (1) 표 형태 구조 데이터에 대한 적용성, (2) 비선형성 및 변수 상호작용 학습 능력, (3) 과적합 제어 가능성, (4) 해석가능성 기법(SHAP 등)과의 결합 용이성, (5) 구조공학 실무에서의 기준선 비교 필요성을 종합적으로 고려한 것이다.
즉, ACI 408 데이터 기반으로 다수 ML 모델(ANN[Rumelhart et al., 1986], RF[Breiman, 2001], GBR[Friedman, 2001], XGBoost[Chen and Guestrin, 2016] , DT[Breiman et al., 1984], MLR[Montgomery et al., 2021])의 성능을 교차검증으로 비교하고 예측 정확도 개선 가능성을 보고하고자 한다. ANN은 다층 퍼셉트론 기반으로 입력–출력 사이의 비선형 관계를 근사하는 모델이다. 충분한 데이터와 적절한 규제 및 구조(은닉층, 활성화 함수 등)를 적용하면 복잡한 비선형·상호작용 효과를 잘 반영할 수 있다. RF는 여러 의사결정나무를 부트스트랩 표본과 무작위 특성 선택으로 학습하여 평균화함으로써 분산을 줄이고 일반화 성능을 확보하는 앙상블 모델이다. 입력 스케일에 비교적 둔감하고, 표형 데이터에서 안정적인 성능을 기대할 수 있다. GBR은 얕은 회귀나무를 순차적으로 추가하면서 손실함수의 기울기 방향으로 모델을 개선하는 부스팅 계열 모델이다. 비선형성과 상호작용을 효과적으로 학습할 수 있으나, 학습률, 나무 깊이 등 하이퍼파라미터에 따라 과적합 민감도가 달라질 수 있다. XGBoost는 부스팅 계열의 대표적 고성능 구현으로, 규제항과 효율적인 학습 전략을 통해 일반화 성능과 계산 효율을 동시에 확보하는 것을 목표로 한다. 구조공학의 다변수 비선형 예측 문제에서 우수한 성능이 자주 보고되는 모델군이다. DT는 입력 공간을 규칙 기반으로 분할하여 예측하는 단일 트리 모델이다. 해석은 직관적이지만 단일 트리는 분산이 커 과적합이 발생하기 쉽다. 본 연구에서는 DT를 단순 기준 모델로 포함하여 앙상블/부스팅의 성능 향상 정도를 비교하였다. MLR은 선형 결합으로 목표값을 예측하는 고전적 회귀 모델로, 비선형성을 충분히 반영하기 어렵다. 다만 기준선으로서 “비선형 모델이 얼마나 개선되는지”를 명확히 보여주기 위해 포함하였다.
3.5 SHAP 기반 해석가능성 분석 및 파일럿 점검
정확도가 높은 모델이라도 구조공학 적용에서는 모델이 어떤 입력에 민감하게 반응하는지, 그리고 그 반응이 물리적으로 타당한지를 점검해야 한다. 이를 위해 본 연구는 SHAP을 활용하여 전역 중요도(전체 데이터에서의 평균 영향)와 국부 기여도(특정 샘플 예측에서 변수별 기여)를 산정하였다. SHAP은 샤플리 값에 기반하여 특성 기여도를 일관된 형태로 정의하는 통합 프레임워크로 제안되었다. SHAP 분석 결과는 (1) ACI 408R-03이 강조하는 지배변수들이 실제로도 높은 기여도를 갖는지, (2) 횡보강 변수(Atr, N 등)가 횡보강 구속 조건에서 예측에 유의미하게 반영되는지, (3) 일부 비정상 예측(과대평가)의 원인이 특정 변수 조합(예: 작은 cmin과 큰 db 등)에 집중되는지 등을 점검하는 데 활용하였다. 이러한 파일럿 점검은 최종 모델을 방호설계 의사결정에 사용하기 위한 필수 단계로 간주하였다.
본 장에서는 ACI 408 데이터베이스를 기반으로, ANN, RF, GBR, XGBoost, DT, MLR의 6가지 알고리즘을 동일한 학습-검증 프로토콜(hold-out test, k-fold 교차검증, Optuna 최적화) 하에서 비교하여 최적 알고리즘을 선정하는 절차를 제시하였다. Optuna를 이용한 하이퍼파라미터 최적화는 교차검증 성능을 기반으로 탐색 효율과 성능 향상을 동시에 도모하며, SHAP 기반 해석가능성 분석은 고정밀 예측 모델의 공학적 신뢰성을 보완하는 도구로 활용된다.
4. AI 기반 부착강도 대체 모델 결과 및 토의
4.1 결과 제시 원칙과 평가 지표
본 장에서는 ACI 408 데이터베이스를 이용해 학습한 6개 기계학습 알고리즘(ANN, RF, GBR, XGBoost, DT, MLR)의 예측 성능을 비교하고, 가장 높은 예측 정확도를 보이는 최적 모델을 선정하였다. 알고리즘 비교는 학습 데이터 기반 교차검증 및 하이퍼파라미터 최적화를 수행한 후, 분리된 시험 데이터에서 최종 성능을 산정하는 방식으로 수행하였다. 성능 평가는 결정계수(R2)와 평균제곱근오차(RMSE)를 기준으로 하며, Table 3에 시험 데이터 성능을 요약하였다. 또한 Fig. 3은 알고리즘별 예측값과 실험값의 산포도를 통해 적합도를 시각적으로 비교한 결과이다.
Table 3
Estimation performance for each algorithm (train and test dataset)
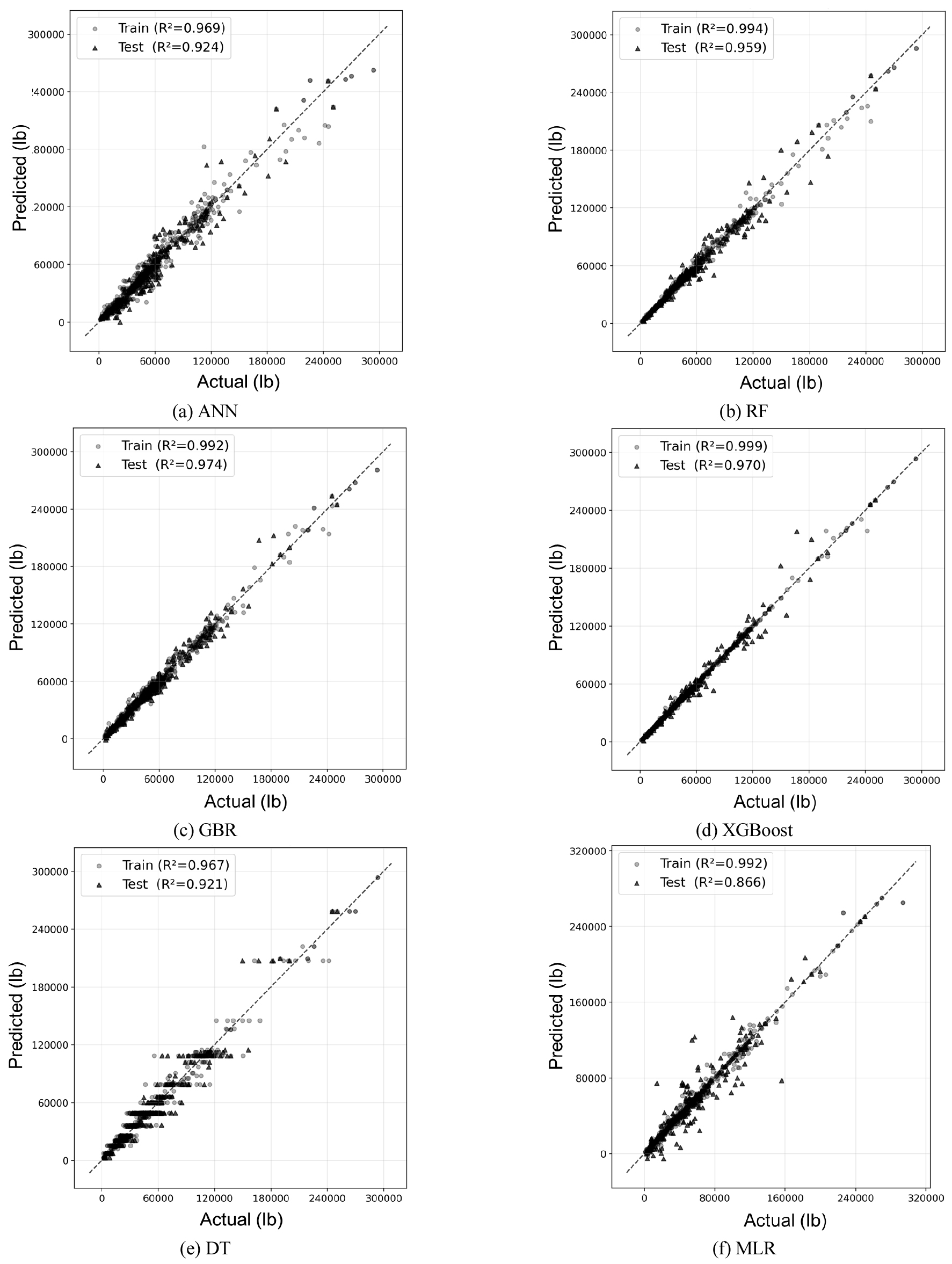
4.2 기준선(ACI 408R-03) 대비 AI 모델의 예측 특성
기준선 모델로는 ACI 408R-03의 서술식 기반 예측 결과를 사용하였다. ACI 408 서술식은 횡보강 유무에 따라 예측 구조가 달라지므로, 데이터 조건에 따라 해당 식을 적용하여 실험값과 비교하였다. 기준선은 전체 경향을 합리적으로 추종하나, 부착 및 정착 거동이 다수 변수의 비선형 결합으로 지배되기 때문에 특정 조건에서 산포가 커지는 경향이 관찰될 수 있다. AI 모델은 동일 데이터에서 함수형을 고정하지 않고 비선형 및 상호작용을 학습함으로써, 전체 적합도를 향상시킬 수 있다.
4.3 알고리즘별 성능 비교 결과
Table 3의 시험 데이터 성능을 기준으로 비교한 결과, ANN, 부스팅, 앙상블 계열의 기계학습이 높은 R2 수준(>0.95)을 보였으며, 테스트 데이터 기준으로 RMSE 측면에서는 GBR이 7111.5로 가장 낮아 최적 모델로 선정되었다. 다음으로 XGBoost(7637.0), RF(8914.9), ANN(12108.1), DT(12361.0), MLR(16128.2) 순으로 오차가 증가하였다. 이는 부착강도 예측 문제가 선형 결합만으로 설명되기 어려운 비선형·상호작용 문제임을 시사하며, 비선형 근사 능력이 큰 모델(ANN, 부스팅, 앙상블 계열)이 높은 정확도를 나타낸 것으로 해석할 수 있다. Fig. 3의 산포도에서도 ANN, GBR, XGBoost, RF는 1:1 선 주변에 데이터가 상대적으로 밀집하는 경향을 보인다. 단일 트리(DT)는 구조가 단순하여 특정 구간에서 편향 또는 분산이 증가하기 쉽고, MLR은 비선형 및 임계 현상을 반영하기 어려워 상대적으로 큰 오차가 나타난다.
알고리즘별 성능 차이는 모델 구조와 데이터 특성의 상호작용으로 설명될 수 있다. (1) MLR(다중선형회귀)은 입력–출력 관계를 선형 결합으로 가정하므로 모델이 단순하고 해석이 용이하지만, ACI 408 데이터에서 나타나는 다변수 비선형성과 변수 간 상호작용을 충분히 반영하기 어렵다. 따라서 기준선 비교에는 유용하나, 복잡한 부착 거동을 설명하는 데에는 근본적 한계가 있어 상대적으로 큰 오차가 발생할 수 있다. (2) DT는 규칙 기반 분할을 통해 비선형성을 일부 반영할 수 있으나, 단일 트리는 학습 데이터의 국부적 패턴에 민감해 분산이 커지고 과적합이 발생하기 쉬워 일반화 성능이 제한될 수 있다. (3) RF(랜덤 포레스트)는 다수의 트리를 부트스트랩 표본과 무작위 특성 선택으로 학습한 뒤 평균화하여 분산을 줄이므로, DT 대비 일반화 성능이 향상되는 경향이 있다. 또한 입력 스케일에 상대적으로 덜 민감하고 표형 데이터에서 안정적인 성능을 보이는 경우가 많다. 다만 평균화 특성상 일부 극단 구간의 세밀한 비선형 패턴을 부스팅 계열만큼 강하게 추적하지 못할 수 있다. (4) GBR 및 XGBoost는 약한 학습기를 순차적으로 추가하여 잔차를 보정하는 부스팅 계열로, 비선형성과 변수 상호작용을 유연하게 학습해 높은 예측 성능을 기대할 수 있다. 특히 XGBoost는 규제항과 다양한 샘플링/학습 전략을 통해 과적합 제어와 계산 효율을 함께 고려할 수 있어, 동일 조건에서 GBR 대비 성능 또는 안정성이 개선되는 경우가 있다. (5) ANN은 비선형 근사 능력이 매우 크며, 충분한 데이터와 적절한 규제, 구조 및 학습 설정이 확보될 경우 복잡한 부착 거동을 효과적으로 모사할 수 있다. 반면 하이퍼파라미터 및 데이터 전처리에 민감하므로, 교차검증과 최적화 절차를 통해 일반화 성능을 확보하는 과정이 중요하다. 본 연구에서는 단순히 예측 평가만이 아닌 추후 논의할 SHAP기반 특징변수 분석을 통해 향후 부착강도 예측에 있어 기계학습 모델을 논의하고자 한다.
4.4 SHAP 기반 특징변수 영향 분석
본 연구의 두 번째 목표는 최종 모델의 예측 정확도를 확보하는 것뿐 아니라, 예측 결과에 영향을 주는 주요 입력 변수를 정량적으로 식별하고 공학적으로 해석하는 것이다. 이를 위해 SHAP을 적용하였다. SHAP summary plot은 전체 시험 데이터에 대해 변수별 기여도 분포를 제공하며, x축의 SHAP 값은 해당 변수가 모델 출력(총 전달력 예측값)을 증가(+) 또는 감소(–)시키는 방향과 크기를 의미한다. 또한 점의 색상(High/Low)은 변수값의 상대적 크기를 나타내므로, 변수값이 커질수록 예측이 증가하는지(또는 감소하는지)의 경향도 함께 파악할 수 있다.
Fig. 4는 시험 데이터에 대해 알고리즘별 전역 SHAP summary plot(상위 6개 변수)을 제시한 결과이며, 각 점은 시험 데이터의 한 샘플을 의미한다. x축은 SHAP 값(해당 변수가 예측 총 전달력 Tb를 증가/감소시키는 기여도), 색은 변수 값의 크기(High/Low)를 나타낸다. y축은 평균 절대 SHAP 값 기준으로 정렬된 상위 6개 영향 변수이다. 전반적으로 모든 모델에서 철근 직경(db), 철근 단면적(Ab), 정착/겹침 길이(ld), 단면 기하(d, b), 피복 계열(cb) 및 재료속성(fyt, fc) 등이 반복적으로 상위 영향 변수로 나타났다. 이는 ACI 408R-03에서 부착·정착 강도를 지배하는 핵심 인자(철근/단면 기하, 정착 길이, 피복·간격 및 구속 조건)가 데이터 기반 모델에서도 중요한 설명 변수로 작동함을 정성적으로 뒷받침한다.
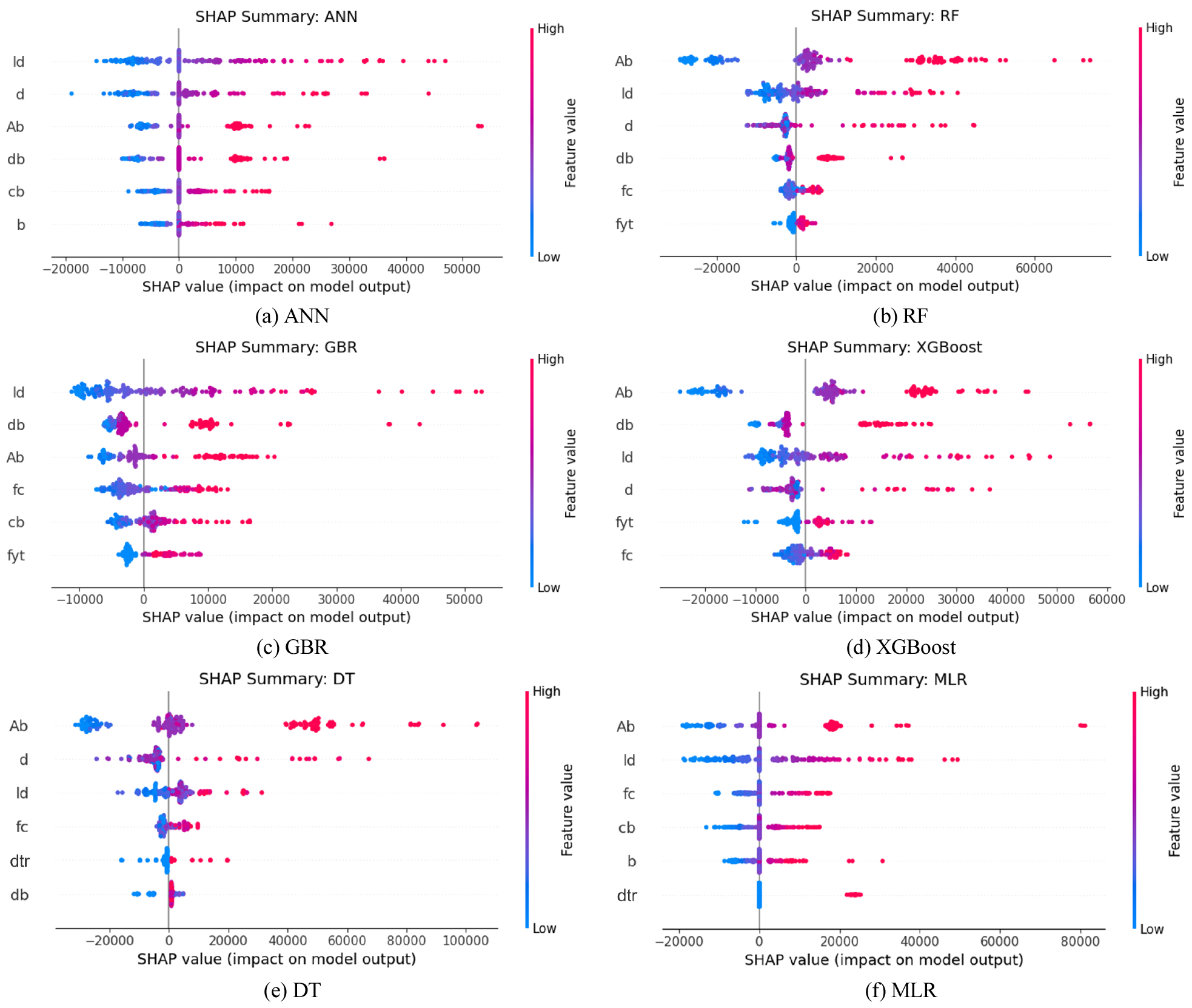
알고리즘별로 상위 변수의 구성에는 차이가 존재한다. 예를 들어, ANN은 ld, d, Ab, db, cb, b가 상위 변수로 나타나 철근 및 단면 기하와 피복 조건을 함께 반영하는 경향을 보이며, RF는 Ab, ld, d, db, fc, fyt가 상위 변수로 나타나 단면 치수와 철근 관련 변수의 상호작용을 비교적 강하게 반영한다. 부스팅 계열(GBR, XGBoost)은 공통적으로 Ab, db, ld에 높은 민감도를 보이되, 일부 모델에서 콘크리트 압축강도(fc)피복/간격 변수(cb) 또는 횡보강 항복강도(fyt)가 상위 변수로 포함되어 구속 효과가 조건부로 학습될 가능성을 시사한다. DT는 Ab, d, ld, fc, dtr, db가 상위 변수로 나타나, 입력 공간을 규칙 기반으로 분할하면서 특정 기하/피복 조건에서의 예측 민감도가 커질 수 있음을 보여준다. MLR은 Ab, ld, fc, cb, b, dtr가 상위 변수로 나타난 특성이 있다.
한편 알고리즘별로 상위 변수의 구성 및 순위가 완전히 동일하지는 않다. 예를 들어 일부 모델(ANN, GBR)에서는 ld가 상대적으로 더 상위에 위치하는 반면, 다른 모델(RF, XGBoost, DT, MLR)에서는 Ab가 최상위에 위치한다. 이는 (1) Ab와 ld가 철근과 콘크리트의 기계적 마찰에 따른 부착강도에 크게 영향을 주고, (2) 학습기가 상관된 변수 중 어느 변수를 “대표 설명 변수”로 선택하느냐가 모델 구조(선형/비선형, 분할 기반/연속 근사 기반)와 규제 방식에 따라 달라질 수 있기 때문이다. 동일한 물리 현상을 서로 다른 변수 표현으로 설명하는 경우가 존재하므로, 이러한 차이를 곧바로 “물리적 모순”으로 해석하기보다는, 변수 상관성 및 표현 중복의 영향과 알고리즘의 귀속 특성 차이로 이해하는 것이 타당하다.
다만, SHAP 결과의 알고리즘 간 차이를 “물리 법칙이 모델마다 다르다”로 단정하는 것은 주의가 필요하다. 표형 데이터에서는 상관성이 큰 변수(예: db와 Ab, 피복 관련 변수들)가 존재하며, 이 경우 동일한 물리적 효과가 알고리즘에 따라 서로 다른 변수로 분산되어 설명될 수 있다(중요도 분해의 비유일성). 따라서 본 연구에서는 SHAP을 (i) 주요 변수군이 합리적인지(철근/정착길이/피복·구속) 점검하는 1차 검증 도구로 활용하되, (ii) 향후에는 부분의존도(Partial dependence) 또는 ICE 분석을 통해 단조성(예: ld 증가 시 예측 증가, 피복 증가 시 splitting 저항 증가)과 같은 물리적 일관성을 추가로 확인하는 것이 바람직하다.
4.5 적용 범위 및 한계
본 연구의 모델은 ACI 408 데이터베이스 범위 내에서 학습·검증되었으므로, Table 1에 제시된 입력 변수 범위를 적용 범위로 간주해야 한다. 즉, 정착/겹침 길이(ld), 철근 직경(db), 피복·간격 변수(cmin, cmax, cso, csi, cb), 단면 치수(b, h, d), 횡보강(Atr, N, fyt) 및 상대 리브면적(Rr) 등이 데이터 분포 범위를 벗어나는 경우(외삽) 모델은 비합리적 예측을 할 수 있으며 오차가 급격히 증가할 수 있다. 따라서 실무 적용 시에는 입력값이 Table 1 범위를 만족하는지 사전 점검하고, 범위를 벗어나는 경우 본 모델 예측을 단독 근거로 사용하지 않는 것이 필요하다.
본 연구의 모델은 ACI 408 데이터베이스 범위 내에서 학습·검증되었으므로, Table 1에 제시된 입력 변수 범위를 적용 범위로 간주해야 한다. 즉, 정착/겹침 길이(ld), 철근 직경(db), 피복·간격 변수(cmin, cmax, cso, csi, cb), 단면 치수(b, h, d), 횡보강(Atr, N, fyt) 및 상대 리브면적(Rr) 등이 데이터 분포 범위를 벗어나는 경우 모델은 비합리적 예측을 할 수 있으며 오차가 급격히 증가할 수 있다. 따라서 실무 적용 시에는 입력값이 Table 1 범위를 만족하는지 사전 점검하고, 범위를 벗어나는 경우 본 모델 예측을 단독 근거로 사용하지 않는 것이 필요하다.
해석가능성 관점에서, Fig. 4에서 나타난 변수 중요도는 알고리즘에 따라 일부 상이하며, 특히 상관성이 큰 변수군에서는 중요도가 분산되어 나타날 수 있다. 따라서 단일 모델의 중요도 순위만으로 지배 메커니즘을 확정하기보다, (i) 주요 변수군의 일관성(철근/정착길이/구속 조건), (ii) 예측–실험 잔차의 집중 구간(특정 db–cmin 조합 등), (iii) 훈련–시험 성능 격차(Table 3) 등을 함께 고려하여 과대적합 가능성을 점검해야 한다. 예를 들어, 훈련 RMSE가 매우 낮으나 시험 RMSE가 상대적으로 커지는 경우에는 데이터 분포가 희소한 고전달력 구간에서의 불확실성이 확대될 수 있으므로, 고하중 영역에서의 잔차 분석 및 샘플 수 보강이 바람직하다.
마지막으로, 방호(폭발·충격) 설계 적용 관점에서는 변형률 속도 효과, 반복/충격 하중 이력, 동적 구속 변화 등 동적 거동 요인이 존재하나, 본 연구는 ACI 408의 정적 실험 데이터베이스에 기반한다. 따라서 본 모델은 현 단계에서 “정적 데이터 기반의 부착/정착 성능 예측기”로 해석해야 하며, 동적 조건으로의 일반화는 추가 연구(동적 실험 데이터 축적 및 별도 검증)가 요구된다.
5. 결 론
본 연구는 ACI 408 데이터베이스를 기반으로 철근 정착 및 겹침이음의 부착강도(총 전달력)를 예측하는 데이터 구동형 AI 대체 모델을 구축하고, 6개 기계학습 알고리즘(ANN, RF, GBR, XGBoost, DT, MLR)의 성능을 동일한 학습 및 검증 프로토콜 하에서 비교하였다. 또한, SHAP 기반 해석가능성 분석을 통해 예측에 영향을 미치는 주요 변수의 기여도를 점검하였다. 주요 결론은 다음과 같다.
(1) 6개 알고리즘 비교 결과, 다소 DT와 MLR가 일부 낮은 성능을 보여줬으나, 대부분의 기계학습 알고리즘이 높은 예측 정확도를 보였다. 이는 기계학습 알고리즘이 철근 정착과 부착강도의 예측에 있어 가능성이 있음을 보여준다.
(2) 시험 데이터 Test set의 성능 기준으로 GBR가 R2 = 0.974, RMSE = 7111.5로 가장 우수한 일반화 성능을 나타냈으며, XGBoost(R2 = 0.970, RMSE = 7637.0), RF(R2 = 0.959, RMSE = 8914.9)이 그 뒤를 이었다. DT와 MLR은 상대적으로 큰 오차를 보여, 부착강도 예측이 선형 결합만으로는 충분히 설명되기 어려운 다변수 비선형·상호작용 문제임을 시사한다.
(3) 예측–실험 산포도(Fig. 3)에서도 ANN, GBR, XGBoost, RF는 1:1 선 주변에 데이터가 상대적으로 밀집하는 경향을 보여, 데이터 기반 비선형 학습기가 ACI 408 서술식 대비 적합도 개선 가능성을 가짐을 확인하였다.
(4) SHAP summary plot(Fig. 4) 분석 결과, 대부분의 모델에서 가 상위 영향 변수로 나타났고, 재료의 형상(db, Ab, ld, d, b, cb) 및 재료의 속성(fyt, fc)와 같은 피복·간격·횡구속 관련 변수도 알고리즘에 따라 주요 변수로 포함되었다. 또한 알고리즘별로 중요도 순서와 기여 패턴이 달라질 수 있음을 확인하여, 구조공학 적용에서는 단순 정확도 향상뿐 아니라 해석가능성 기반의 물리적 타당성 점검이 과대적합 및 비물리적 민감도 완화에 유효함을 시사한다.
(5) 본 연구의 모델은 ACI 408 데이터 범위 내에서 학습·검증되었으므로, 외삽 조건 적용에는 주의가 필요하다. ACI 408R-03 경험식 입력만으로 대체 모델을 제안하려면 입력 변수 집합을 엄밀히 제한한 재학습 및 재검증이 요구된다. 향후 연구에서는 외부 데이터셋을 통한 외부 검증과 더불어, 적용 범위·입력 변수 정의·데이터 품질 기준을 포함하는 실무적 가이드라인 제시가 필요하다.
