

1. 서 론
2. 지하 수소저장시설 폭발에 따른 지반 진동 시뮬레이션
2.1 구성방정식
2.1.1 Coupled Eulerian-Lagrangian(CEL) 모델
2.1.2 Mohr-Coulomb(MC) 모델
2.2 수치모델링
2.3 매개변수해석 결과
3. 지반 진동치 예측 모델 개발
3.1 데이터 전처리
3.1.1 데이터 증폭
3.1.2 이상치 제거
3.2 최대 진동치 예측 모델 개발 및 검증
3.2.1 입/출력인자의 상관성 분석
3.2.2 예측 모델의 신뢰성 검증
4. 결 론
1. 서 론
최근 친환경 에너지원으로서 수소의 활용이 증가함에 따라, 대규모 수소 저장시설에 대한 연구가 활발히 진행되고 있다. 특히, 지하 수소저장시설은 지상 저장시설에 비해 폭발 위험이 상대적으로 낮고, 외부 충격으로부터 보호될 수 있는 장점이 있지만, 폭발 발생 시 지반 및 주변 구조물에 미치는 영향에 대한 연구는 아직 부족한 실정이다(Park et al., 2021). 수소는 높은 확산성과 낮은 점화 에너지를 가지며, 공기와 혼합될 경우 강력한 폭발을 유발할 수 있어, 지하 수소저장시설에서의 폭발은 매우 높은 동적 하중을 발생시키며 지반과 구조물의 안정성에 중대한 영향을 미칠 수 있다. 이에 따라, 지하 수소저장시설에서의 폭발로 인해 발생하는 지반 진동을 정량적으로 평가하고, 이를 기반으로 피해 예측 및 방호 대책을 마련하는 것이 필수적이다.
지하 폭발에 대한 기존 연구들은 주로 군사적 목적의 지하 구조물 또는 일반적인 지반 폭발을 대상으로 수행되어 왔다(Kim et al., 2003; Lee et al., 2021; Ryu et al., 2021). 이러한 연구들은 폭발 압력파의 전파 메커니즘과 지반 변형에 대한 기본적인 해석 기법을 제공하지만(Choi et al., 2022), 지하 수소저장시설의 폭발 특성과 지반의 동적 거동을 체계적으로 분석한 연구는 제한적이다. 따라서 본 연구에서는 비선형 유한요소해석(Finite Element Analysis, FEA) 기법을 활용하여 지하 수소저장시설에서 발생하는 폭발이 지반 진동에 미치는 영향을 분석하고, 이를 정량적으로 평가할 수 있는 방법론을 제시하고자 한다. 이를 위해 Coupled Eulerian-Lagrangian(CEL) 모델과 Mohr-Coulomb(MC) 모델을 적용하여 폭발 하중에 따른 지반의 동적 거동을 해석하고, 수소 농도, 토피고, 지반 조건 등의 매개변수 변화에 따른 폭발 영향을 분석하였다.
또한, 본 연구에서는 지하 수소저장시설 폭발로 인해 발생하는 지반 진동을 보다 정확하게 예측하기 위해 인공지능(Artificial Intelligence, AI) 기반의 예측 모델을 개발하였다. AI 기술은 복잡한 비선형 시스템을 학습하고 분석하는 데 강점을 가지며, 최근 다양한 공학 분야에서 예측 모델 개발을 위한 중요한 도구로 활용되고 있다. 본 연구에서는 심층 신경망(Deep Neural Network, DNN) 알고리즘을 적용하여 지반 진동을 예측하고, 데이터 증폭 기법을 활용하여 모델의 학습 성능을 향상시켰다. 특히, SMOTE(Synthetic Minority Over-sampling Technique), Borderline-SMOTE, ADASYN(Adaptive Synthetic Sampling), CTGAN(Conditional Tabular GAN) 등의 오버샘플링 기법을 적용하여 데이터 부족으로 인한 예측 성능 저하를 방지하고, 이상치 제거를 통해 모델의 신뢰성을 확보하였다.
2. 지하 수소저장시설 폭발에 따른 지반 진동 시뮬레이션
다양한 수소 폭발 시나리오에서 주변 구조물 손상을 정확히 예측하기 위해 3차원 수치 시뮬레이션은 필수적이다. 특히, 지하 수소저장시설 내부에서 발생하는 가스 폭발은 지반과의 상호작용을 포함하여 정밀한 해석이 요구되며, 이를 위해 비선형 유한요소해석(Finite Element Analysis, FEA) 기법을 적용할 수 있다. 본 연구에서는 비선형 유한요소해석 프로그램인 ABAQUS를 활용하여 지하 수소저장시설 내부 가스 폭발로 인한 주변 지반의 동적 응답을 분석하고, 이격 거리별 최대진동치 데이터베이스(Data base, DB)를 구축하였다.
2.1 구성방정식
폭발로 인해 발생하는 동적 거동과 폭발 하중에 대한 지반의 전단 강도 및 파괴 거동을 모사하기 위해 CEL 모델과 MC 모델을 적용하여 폭발 하중에 따른 지반의 역학적 거동을 평가하였다.
2.1.1 Coupled Eulerian-Lagrangian(CEL) 모델
폭발처럼 대변형을 발생하는 동적 거동을 수치해석적으로 처리할 때, 주요한 도전 과제는 접촉 문제(Contact problem)와 요소 왜곡(Element distortion)을 효과적으로 해결하는 것이다. 특히, 요소 왜곡은 해석의 수렴성을 저하시킬 뿐만 아니라 물리적으로 부정확한 결과를 초래할 수 있다. 이를 극복하기 위해 CEL 모델링 기술을 적용할 수 있다.
CEL 모델링 기술은 Noh(1964)가 최초 제안한 기법으로, Lagrange 및 Eulerian 기법의 장점을 결합하여 요소 왜곡과 재료 흐름 문제를 완화할 수 있다(Zaid et al., 2022). CEL 모델은 문제 특성에 따라 Euler mesh와 Lagrange mesh를 함께 사용하며, 상호작용 인터페이스에서 페널티 함수(Penalty function) 기반의 접촉 모델을 적용하여 보다 정확한 해석이 가능하도록 한다. 폭발파의 동적 전파를 해석하기 위한 CEL 모델의 지배방정식은 연속방정식(Continuity equation), 운동량 방정식(Momentum equation), 에너지 보존 방정식(Energy conservation equation)으로 구성되며, 식 (1)~식 (3)과 같이 표현할 수 있다.
여기서, ρ는 공기의 밀도, ν는 공기의 유속 벡터, σ는 Cauchy stress 텐서, b는 unit resultant force 텐서, E는 에너지, Q는 열전도도를 의미한다. 위 방정식들은 폭발로 인해 급격히 변화하는 유체의 질량, 운동량 및 에너지 보존을 만족하도록 설정되며, CEL 모델을 통해 지반과 폭발파의 상호작용을 보다 정밀하게 모사할 수 있다.
2.1.2 Mohr-Coulomb(MC) 모델
MC 모델은 지반공학 및 암반공학 분야에서 널리 사용되는 소성 모델 중 하나로, 지반의 전단 강도 및 파괴 거동을 효과적으로 모사할 수 있어 다양한 수치해석 연구에 적용되고 있다(Nazem et al., 2012). Mohr-Coulomb 파괴기준은 지반 재료를 모델링할 때 중간 주응력(Intermediate principal stress)이 파괴에 영향을 고려하지 않으며, Mohr 원의 자오선과 파괴포락선이 직선으로 간주된다는 특징이 있다. 이로 인해 마찰각과 구속압의 변화에 따른 비선형 거동을 완전히 반영하지 못하는 한계점이 존재한다.
MC 소성모델의 항복면(Yield surface)은 MC 파괴모델의 파괴면과 동일하지만, Associated flow rule을 적용할 경우 전단변형 시 모래의 다일러턴시(Dilatancy) 현상이 과대평가되는 문제가 발생할 수 있다. 이를 보완하기 위해 Non-associated flow rule이 적용되며, 소성잠재함수(Plastic potential function)를 활용하여 보다 현실적인 거동을 모사한다. 그러나 일반적인 구속압 범위 내에서는 높은 신뢰성과 사용의 용이성 때문에 MC 모델은 여전히 널리 활용되는 파괴 모델이며, 식 (4)와 같이 표현된다.
여기서, τ는 최대 전단응력, c는 점착력, σ는 수직 응력, Φ는 내부 마찰각이다.
2.2 수치모델링
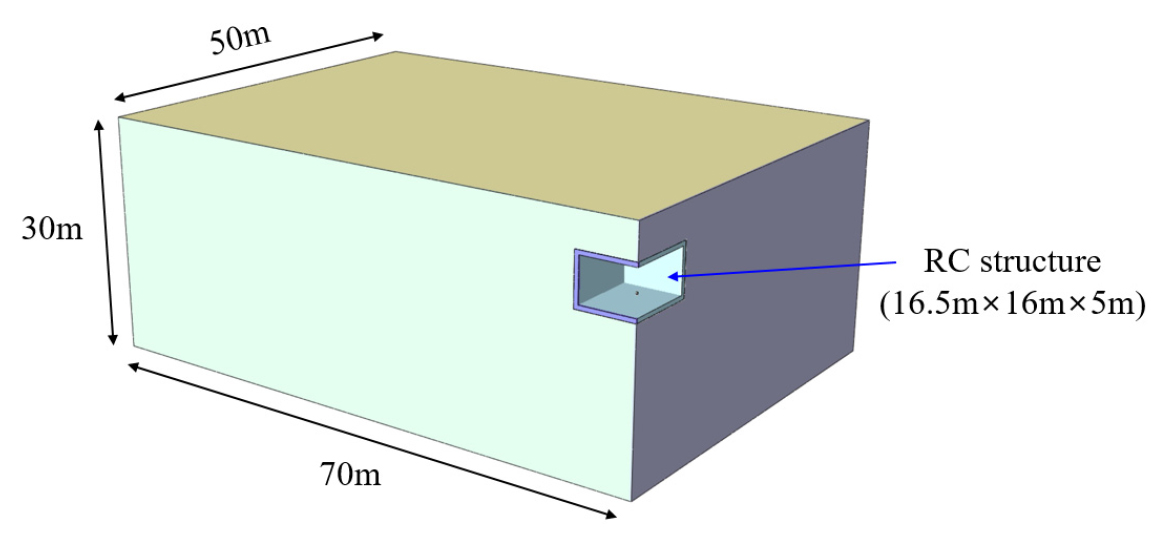
본 연구에서는 지하 수소저장시설 폭발 시 발생하는 지반 진동을 수치적으로 분석하기 위해 단일 지반조건을 가정하였으며, 해석 효율성을 고려하여 축 대칭 모델을 적용하고 1/4 단면만 모델링하였다. 지하 수소저장시설의 규모는 300 kg/day급 수소충전소를 고려하여 폭 16.5 m, 길이 16 m, 높이 5 m로 설정하였으며, 철근콘크리트 벽체의 두께는 0.5 m로 일괄 적용하였다. 경계조건에 대한 영향을 최소화하기 위하여 길이 및 깊이 방향으로 충분한 크기의 해석 도메인을 구축하였다(Fig. 1).
수소가스 폭발 해석에서는 폭발 압력을 간접적으로 예측하는 방법으로 등가 TNT 모델(Equivalent TNT model)이 널리 사용되며, 기존 선행 연구에서도 이를 활용한 수소 폭발 시뮬레이션이 수행되어 왔다(Go et al., 2023). 이를 기반으로 등가 TNT 질량을 평가하는 경험식(식 (5))이 제안되었다(Molkov and Dery, 2015; Lee et al., 2021; Ryu et al., 2021).
여기서, MTNT는 등가 TNT 질량(kg), Mf는 저장된 수소의 질량(kg), E는 폭발에너지(kJ), QTNT는 TNT의 발열량, QH2는 수소의 발열량, η는 가스구름 중 폭발에 기여하는 폭발수율을 의미한다. TNT와 수소의 발열량은 각각 4.6 MJ/kg 및 119.93 MJ/kg이다. 일반적으로 폭발수율(η)은 개방된 공간에서 0.5~3 %, 부분 밀폐 공간에서 3~10 %, 완전 밀폐된 공간에 대하여 10~30 %를 적용하며, 본 논문에서는 Lopes and Melo(2011)의 실내 실험 결과를 참고하여 4 %(0.04)를 적용하였다.
등가 TNT 폭발물의 폭발 압력은 Jones-Wilkins-Lee Equation of State(JWL-EOS) 모델을 적용하여 해석할 수 있으며, 식 (6)과 같이 산정된다(Zaid et al., 2022).
여기서, A, B, R1, R2 및 x는 등가 TNT 재료에 관한 상수, ω는 가우시안 계수이다. V는 폭약의 상대부피(relative volume, V1/V0)를 의미한다(Larcher and Casadei, 2010). 위 식에서 첫 번째 및 두 번째 항은 폭발 초기에 발생하는 고압의 크기를 나타내며, 세 번째 항은 폭발 후 체적 증가에 따른 저압 영역을 표현한다.
수소가스 폭발 시 실제 대기 조건을 반영하기 위해 이상기체 상태 방정식을 적용하였으며, 대기압과 상온 조건에서 공기의 밀도는 1.25 kg/m3, 기체상수는 287 J/kg/K, 비열은 1,004 J/kg/K를 사용하였다.
폭발 압력이 전파되는 과정에서 불필요한 반사파를 최소화하고 해석 결과의 정확도를 확보하기 위하여 해석 도메인의 하부경계조건으로는 고정단 지지를 적용하였으며, 도메인의 전면에는 x 방향 고정단과 y, z 방향 롤러 조건을 적용하였다. 도메인의 우측면에는 z 방향 고정단과 x, y 방향 롤러 조건을, 도메인의 좌측면에는 z 방향 고정단을, 후면에는 x 방향 고정단을 각각 적용하였다.
2.3 매개변수해석 결과
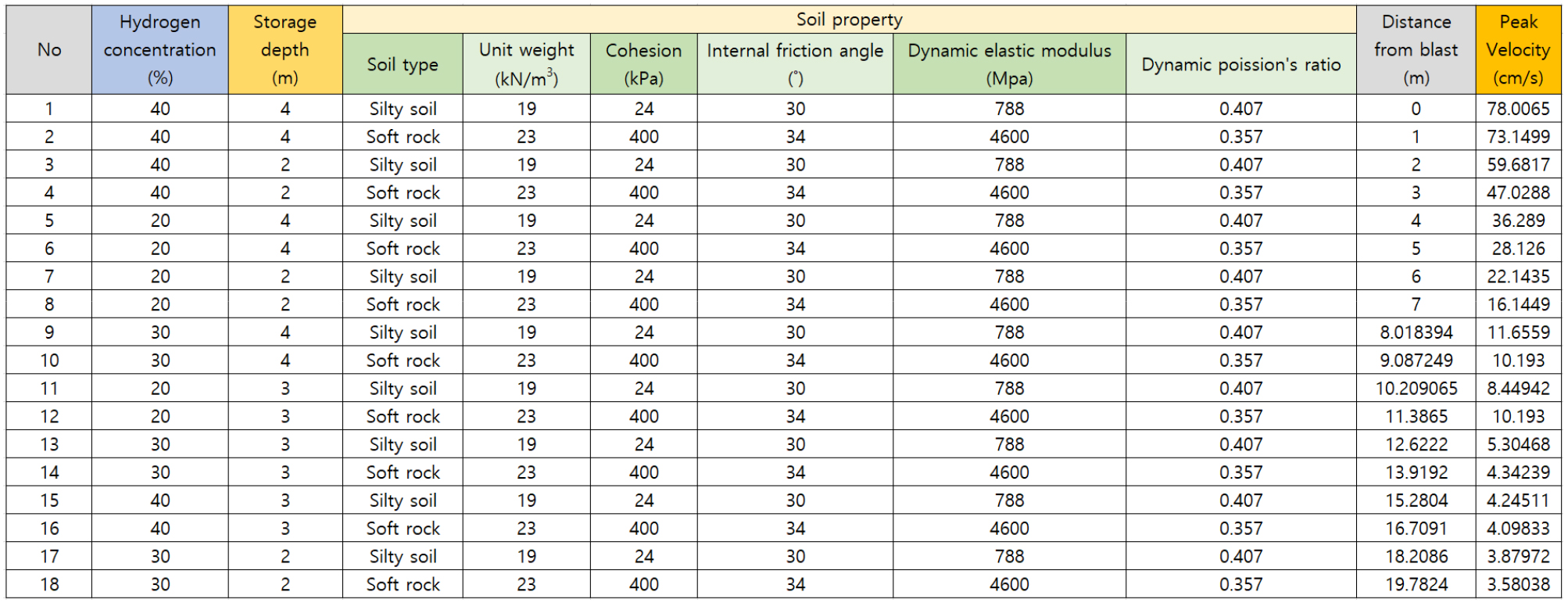
폭발 및 지반 조건에 따른 주변 지반의 거동을 분석하기 위하여 매개변수해석을 수행하였으며, 매개변수의 종류는 수소농도(20, 30, 40 %), 토피고(2, 3, 4 m), 지반조건(실트, 연암)로 총 18 case를 선정하였다. 이 때, 300 kg/day급 수소충전소에서 누출된 수소가스에 의해 지하 수소저장시설의 내부 수소농도가 20, 30, 40 %로 조성된 상태에서 폭발이 발생한 사고 시나리오를 가정하였으며, 수소농도 20, 30, 40 % 조건에 대한 등가 TNT량은 각각 19.2, 28.7, 38.3 kg으로 산정되었다. 지반조건의 경우에는 지반 물성치에 따른 민감도를 분석하기 위하여 수소농도와 토피고를 각각 40 % 및 4 m로 고정하고 지반 물성치를 일정 범위 내에서 임의 생성하여 총 200 case를 추가 생성하였다(Table 1). 따라서 총 218 case에 대한 매개변수해석을 수행하였다.
Table 1
Geotechnical properties applied to numerical analysis
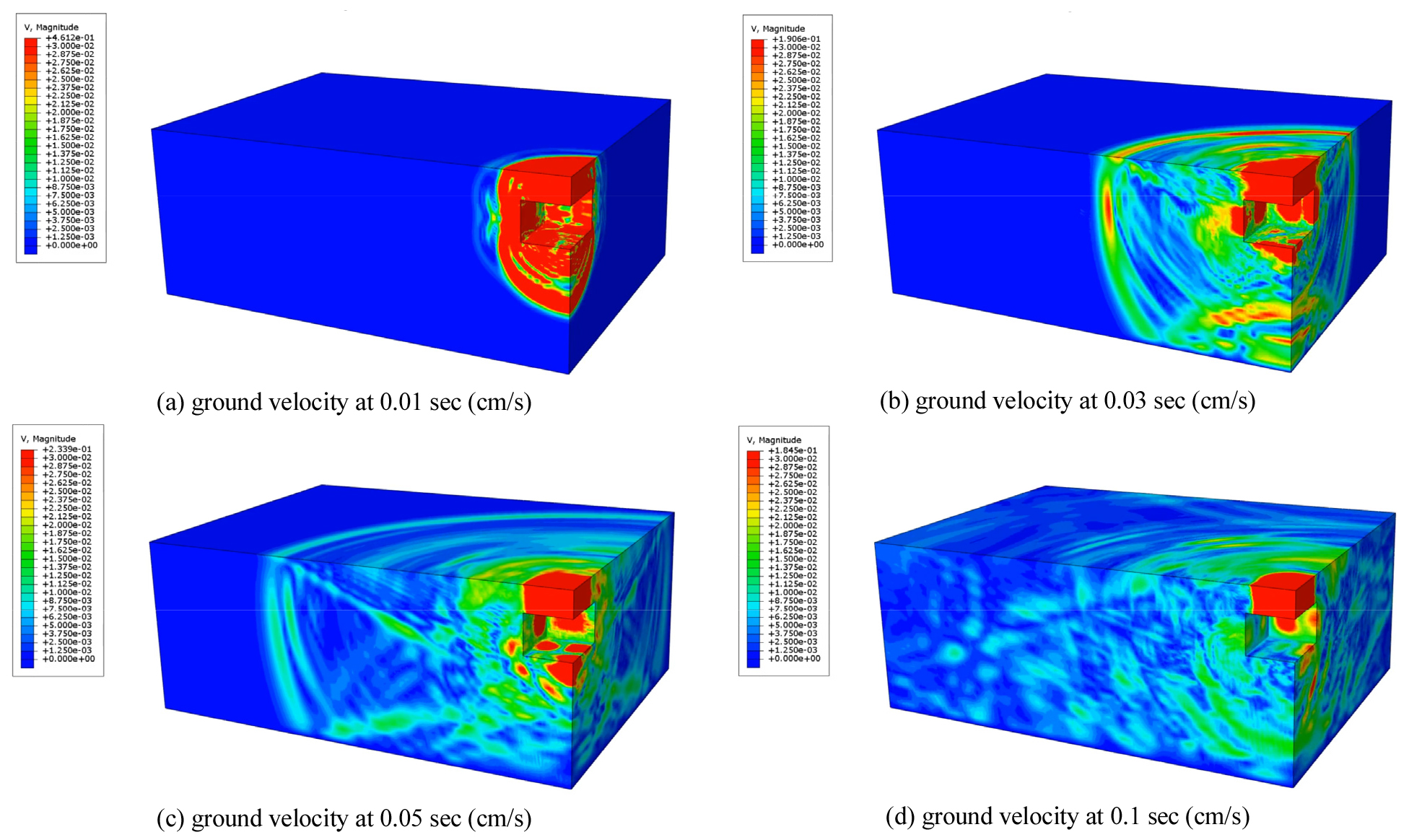
본 연구에서는 이격 거리별 최대 진동치 DB를 구축하기 위하여 지하 수소저장시설 직상부로부터 이격 거리 70 m까지 총 37개의 Probe를 설치하여 시간에 따른 지반 진동을 분석하였다(Fig. 2). 매개변수해석 결과, 지하 수소저장시설 직상부의 경우에는 지반의 단위중량이 최대 진동치에 가장 큰 영향을 미치는 것으로 분석되었으며, 이격 거리가 먼 경우에는 지반의 동적 물성치(동탄성계수, 동포아송비)가 최대 진동치에 대한 주요영향인자로 평가되었다.
3. 지반 진동치 예측 모델 개발
지하 수소저장시설 폭발로 인해 발생하는 지반 진동을 보다 정확하게 예측하기 위해 AI 기반의 예측 모델을 개발하였다. 매개변수해석을 통해 수집된 데이터를 활용하여 AI 기반 지반 진동치 예측 모델을 구축하고, 모델의 성능을 검증하기 위해 테스트 손실(Test loss)과 평균제곱오차(Mean squared error, MSE)를 평가하였다.
3.1 데이터 전처리
총 218개의 매개변수해석 결과에서 이격 거리별 Probe 측정값을 추출하여 총 8,066건의 최대 진동치 데이터베이스를 구축하였다(Fig. 3). 본 연구에서는 AI 모델의 학습 성능을 향상시키기 위해 데이터 증폭 및 이상치 제거를 포함한 데이터 전처리 과정을 수행되었다.
3.1.1 데이터 증폭
AI 기반 예측 모델의 성능을 높이기 위해서는 충분한 양의 데이터가 필요하다. 그러나 원본 데이터만으로는 일부 이격 거리에서 데이터가 부족할 가능성이 있으며, 이는 모델이 특정 거리 구간에서 과적합(Overfitting)되는 문제를 초래할 수 있다. 이를 해결하기 위해 오버샘플링 기법을 활용하여 데이터를 증폭함으로써, 데이터의 균형을 맞추고 모델의 일반화 성능을 향상시키고자 하였다.
데이터 증폭 기법으로는 SMOTE, Borderline-SMOTE, ADASYN, 그리고 CTGAN을 적용하였다. 각 기법은 소수 클래스의 데이터를 증폭하는 방식에 차이가 있으며, 다양한 방식으로 데이터를 증강함으로써 소수 클래스의 데이터가 다수 클래스와 균형을 이루도록 한다. SMOTE와 Borderline-SMOTE는 새로운 데이터를 기존 데이터 포인트의 근처에서 생성함으로써 소수 클래스의 분포를 확장시키며, ADASYN은 소수 클래스와 다수 클래스 간의 경계를 고려하여 데이터를 증강한다. CTGAN은 더욱 복잡한 분포를 학습하고 재현할 수 있는 GAN(Generative Adversarial Network)을 활용하여, 소수 클래스의 데이터를 생성하는 방법을 제공한다.
데이터 증폭 후, 각 기법을 적용한 데이터의 분포를 시각화하여 분석하였다(Fig. 4). SMOTE, Borderline-SMOTE, ADASYN 기법을 사용한 경우, 데이터의 분포가 원본 데이터와 유사하게 유지되었으며, 이로 인해 원본 데이터의 특성을 잘 유지하면서도 데이터의 양을 효과적으로 증가시킬 수 있음을 확인하였다. 반면, CTGAN 기법을 적용하여 5배 증폭한 데이터의 경우, 원본 데이터와 비교했을 때 최댓값에서 약 2.5 m, 중간값에서 약 0.8 m, 최솟값에서 약 0.4 m의 차이가 발생하여 데이터 분포가 변형되는 현상이 나타났다. 이는 CTGAN 기법이 원본 데이터의 특성을 충분히 반영하지 못하고, 오히려 데이터의 분포를 왜곡할 가능성이 있음을 의미한다. 따라서 CTGAN을 사용할 경우, 생성된 데이터의 분포를 사전에 검토하고 추가적인 조건을 설정하는 것이 필요하다.
최대 진동치 원본 데이터의 최댓값은 1.13 m/s, 중간 값은 0.2 m/s, 최솟값은 0.04 m/s로 나타났음. SMOTE, Borderline-SMOTE, ADASYN 기법은 각각의 데이터 분포가 원본 데이터와 비교했을 때 최댓값에서 약 0.1~0.2 m/s의 오차를 보였으나, 전체적인 분포는 원본 데이터와 유사하게 나타났다. 그러나 CTGAN 기법을 적용한 경우, 최댓값에서 약 0.18 m/s, 중간값에서 약 0.04 m/s, 최솟값에서 약 0.13 m/s의 차이가 발생하여, 원본 데이터의 특성을 왜곡하는 경향이 관찰되었다. 이러한 결과는 CTGAN이 다른 오버샘플링 기법에 비해 데이터의 다양성을 크게 증가시킬 수 있다는 장점이 있지만, 동시에 데이터의 특성을 충분히 반영하지 못할 수 있다는 단점을 가지고 있음을 의미한다. 따라서 CTGAN을 사용할 때는 원본 데이터의 특성을 충분히 반영할 수 있도록 매개 변수를 조정하고, 생성된 데이터의 분포를 사전에 검토하는 것이 필요하다.
3.1.2 이상치 제거
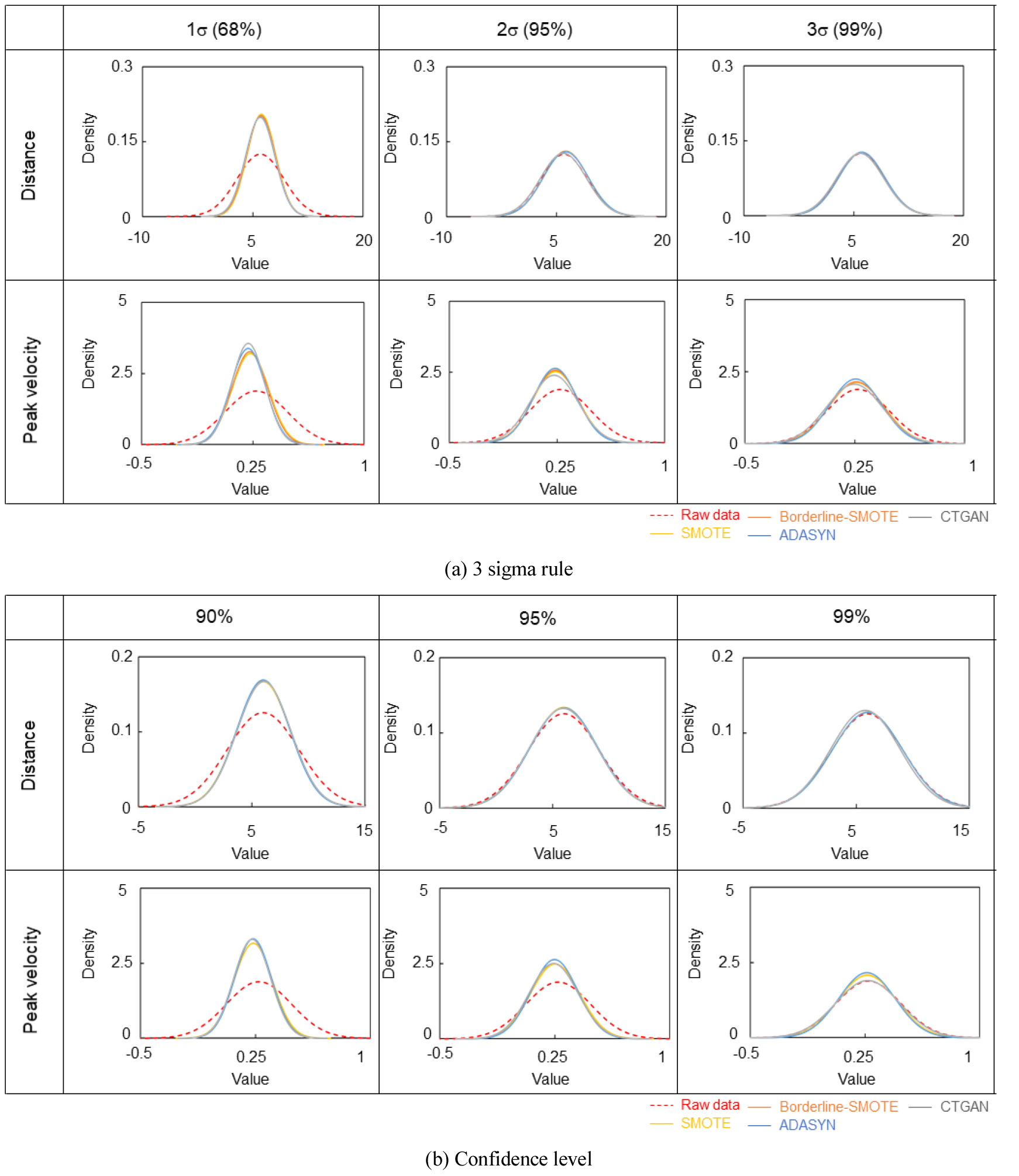
데이터 셋에 포함된 극단적인 값(Outliers)은 모델의 학습 성능을 저하시킬 가능성이 있다. 이상치가 포함될 경우, 모델이 특정한 값에 지나치게 민감하게 반응하여 예측의 신뢰성이 떨어질 수 있기 때문이다. 이에 따라, 본 연구에서는 이상치를 제거하여 데이터 품질을 향상시키고 모델의 일반화 성능을 높이고자 하였다. 이상치 제거 방법으로는 3-Sigma rule과 신뢰구간추정법(Confidence interval method)을 적용하였다. 3-Sigma rule은 정규분포를 따르는 데이터에서 평균(μ)과 표준편차(σ)를 활용하여, 평균에서 ±3σ를 벗어나는 데이터를 이상치로 간주하고 제거하는 방식이다. 이 방법을 적용하면 약 99.7 %의 데이터가 유지되며, 극단적인 값만 제거할 수 있다. 신뢰구간추정법은 신뢰 수준(90, 95, 99 %)을 적용하여, 특정 신뢰 구간 내에서 데이터를 유지하고 이상치를 제거하는 방식이다. Fig. 5에 3-Sigma rule과 신뢰구간추정법을 통한 이상치 제거 결과를 나타내었다. 빨간색 점선은 원본 데이터를, 노란색 실선은 SMOTE, 주황색 실선은 Borderline-SMOTE, 파란 선은 ADASYN, 회색 선은 CTGAN을 의미한다.
이상치 제거 후, 데이터의 평균값과 분포를 분석한 결과, 3-Sigma rule을 적용한 경우 데이터의 평균값이 6으로 일정하게 유지되었으며, 밀도 값은 1σ, 2σ, 3σ 구간에서 동일하게 나타나 데이터의 안정성이 유지되었음을 확인하였다. 최대 진동치(PGV)의 경우 평균값이 1σ 및 2σ에서 0.22로 비슷한 값을 보였으며, 3σ에서는 0.25로 다소 증가하는 경향을 나타냈다. 이로 인해 이상치 제거 후에도 데이터 내에서 최대 속도의 변화가 일부 유지되고 있으며, 3σ에서는 이러한 변화가 상대적으로 커진다는 점을 확인하였다.
신뢰구간추정법을 적용한 경우, 신뢰구간이 90, 95, 99 %일 때 각각 5.98, 5.93, 5.90으로 측정되었으며, 신뢰 구간이 증가할수록 데이터 분포가 점차 수렴하는 경향을 보였다. 이를 통해, 데이터의 안정성을 높이는 데 있어 3-Sigma rule과 신뢰구간추정법이 모두 효과적인 것으로 나타났다.
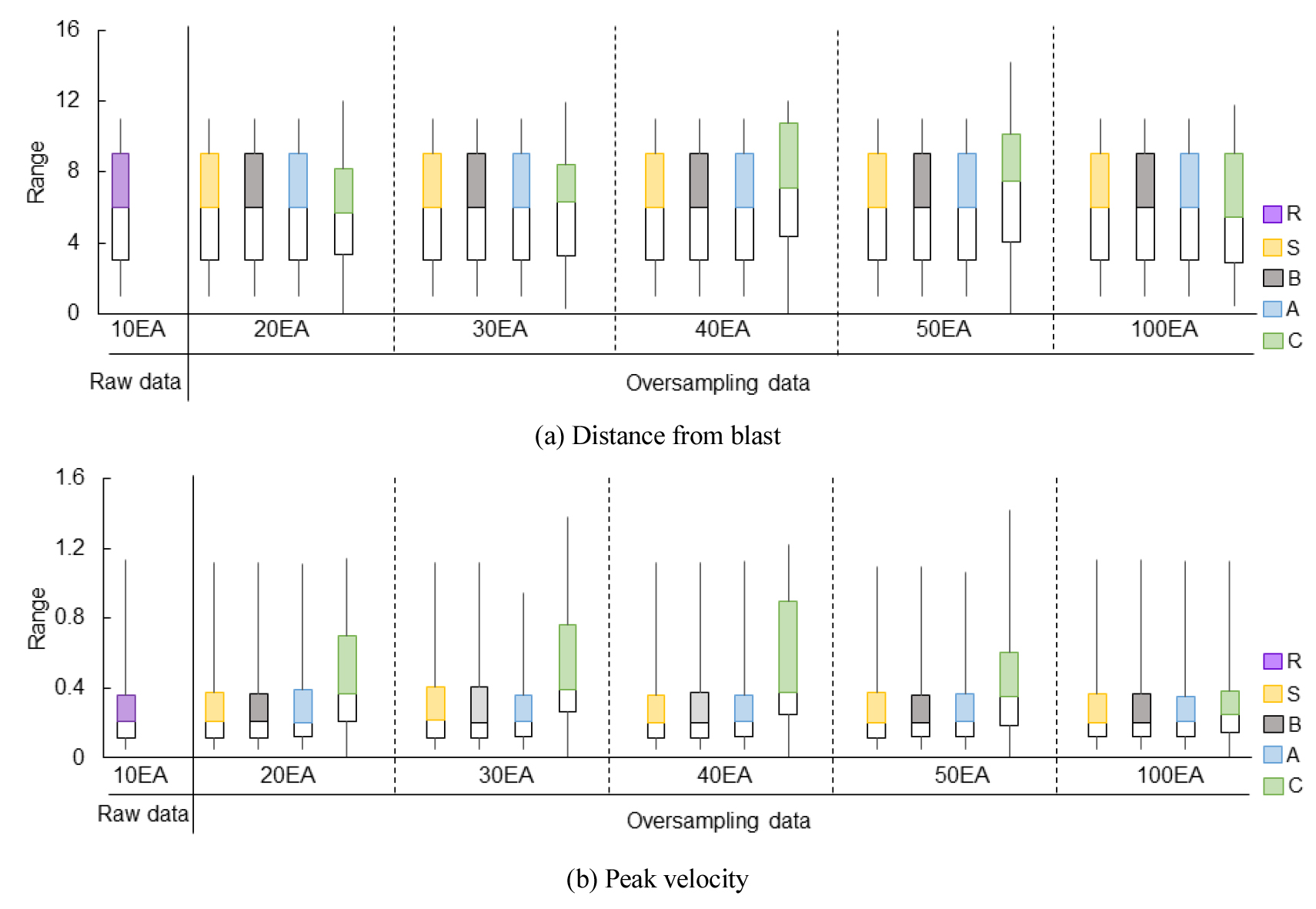
원 데이터를 기준으로 측정한 이격 거리 값의 특성은 최댓값이 0.12, 평균값이 5.9로 나타났다. 이격 거리는 데이터 내에서 특정한 지점 간의 거리 분포를 나타내는 중요한 요소로, 모델이 학습할 때 중요한 역할을 한다. 반면, 최대 진동치의 경우 최댓값은 1.87, 평균값은 0.26으로 분석되었다. 최대 진동치는 데이터가 어떻게 변동하는지, 그리고 그 변동이 어느 정도 급격하게 일어나는지를 보여주는 지표로 작용하며, 데이터 분석에서 중요한 역할을 한다. 데이터를 보다 정교하게 분석하기 위해 3-Sigma rule을 적용하여 이상치를 제거하였다.
3.2 최대 진동치 예측 모델 개발 및 검증
전처리가 수행된 최대 진동치 데이터 셋을 활용하여 인공지능 기반의 지반 진동치 예측 모델을 개발하였다. 딥러닝 알고리즘을 활용하여 DNN 모델을 구축하고, 증폭된 데이터 셋을 기반으로 학습 및 검증을 진행하였다.
3.2.1 입/출력인자의 상관성 분석
다양한 오버샘플링 기법을 적용하여 데이터 증폭 정도에 따른 DNN 모델의 학습 결과를 분석하였다. 증폭된 데이터의 개수에 따른 DNN 모델의 학습 및 검증 손실(Validation loss 및 Training loss) 변화를 시각적으로 표현하였으며(Fig. 6), 각 오버샘플링 기법의 성능을 비교하였다. 실선은 Validation loss, 점선은 Training loss 결과를 의미한다. 또한, 오버샘플링을 통해 증폭된 데이터는 2배, 3배, 4배 5배 그리고 100배는 각각 파란색, 주황색, 검은색, 노란색 그리고 녹색으로 표시하였다.
오버샘플링 기법으로는 SMOTE, Borderline-SMOTE, ADASYN, 그리고 CTGAN을 적용하였다. 증폭된 데이터의 배수는 각각 2배, 3배, 4배, 5배 및 100배로 설정하였으며, 학습 손실과 검증 손실을 분석하여 모델의 수렴 특성을 파악하였다.
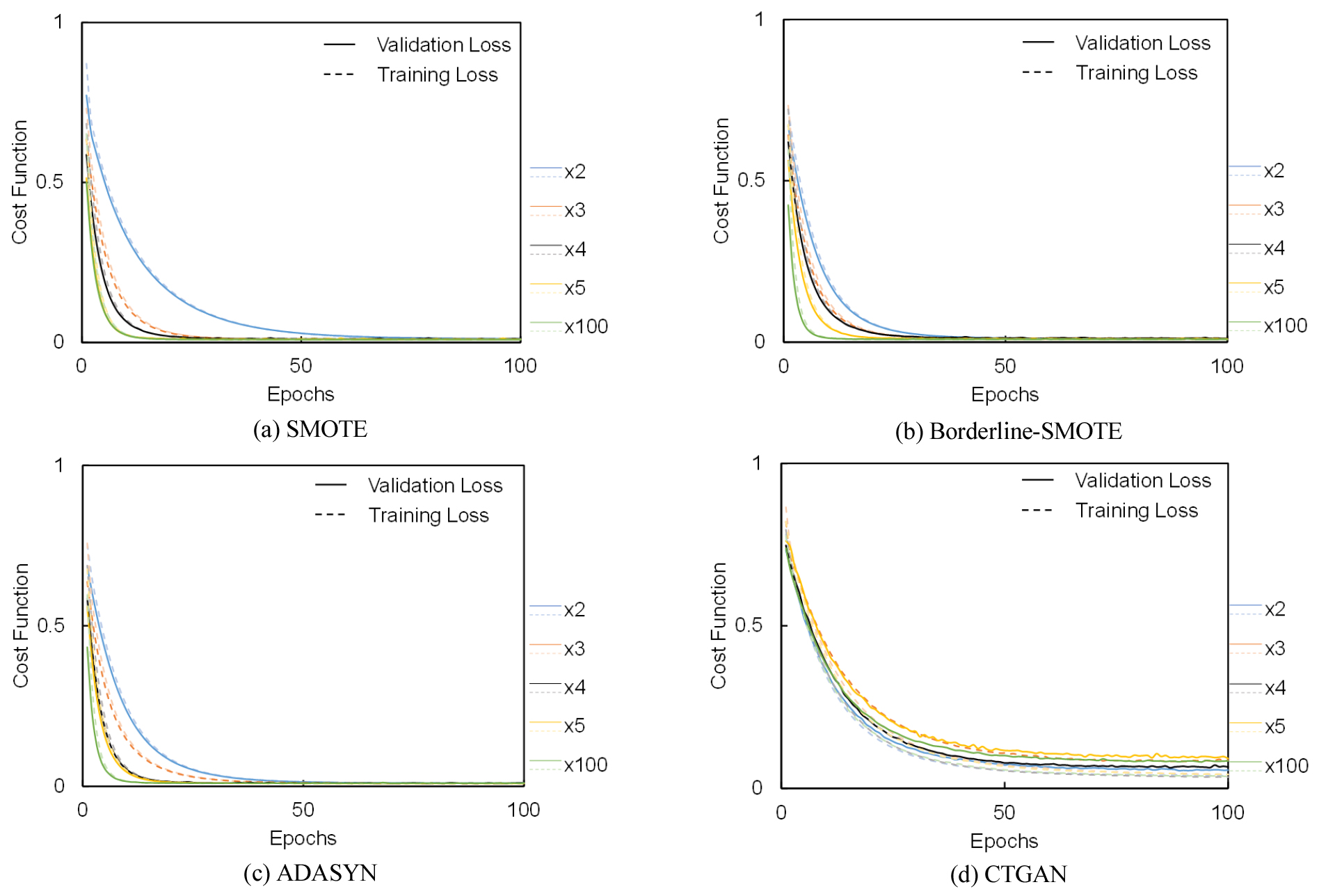
SMOTE 기법을 적용한 경우, 학습 초기 단계에서는 모든 증폭 배수에서 학습 손실과 검증 손실이 급격히 감소하는 경향을 보였다. 이후, 약 20 epoch 이후부터 점진적으로 수렴하는 경향을 나타냈다. 데이터가 2배 증폭된 경우, 검증 손실이 0.9에서 시작하여 50 epoch 이후 0.1 이하로 감소하였으며, 학습 손실은 0.85에서 시작하여 최종적으로 0.05 이하로 수렴하였다. 증폭 배수가 증가할수록 학습 및 검증 손실의 감소 속도가 빨라지는 경향을 보였다. 3배 증폭된 경우, 검증 손실은 0.7에서 시작하여 40 epoch 이후 0.05 이하로 감소하였고, 학습 손실 역시 유사한 양상으로 0.1 이하로 수렴하였다. 4배 및 5배 증폭된 경우에도 비슷한 경향을 나타냈으며, 검증 손실이 0.6에서 0.02까지 더 빠르게 감소하였다. 100배 증폭된 경우, 초기 검증 손실이 0.5로 가장 낮게 시작하여, 30 epoch 이후 0.01 이하로 급격히 수렴하는 양상을 보였다.
Borderline-SMOTE 기법을 적용한 경우, 학습 초기에는 SMOTE와 유사한 양상을 보였으나, 증폭 배수에 따른 손실 변화의 차이가 더욱 명확하게 나타났다. 2배 증폭된 경우, 초기 검증 손실이 0.8에서 시작하여 50 epoch 이후 0.2까지 서서히 감소하였으며, 학습 손실은 0.75에서 시작하여 최종적으로 0.05 이하로 수렴하였다. 증폭 배수가 증가할수록 검증 손실이 점진적으로 감소하였으며, 5배 증폭된 경우에는 검증 손실이 0.6에서 시작하여 20 epoch 이후 0.01 이하로 급격히 감소하였다. 100배로 증폭된 경우, 검증 손실이 0.5에서 시작하여 10 epoch 이후 0.01 이하로 가장 빠르게 수렴하는 특성을 보였다.
ADASYN 기법을 적용한 경우, 초기 손실 값이 다른 기법에 비해 다소 높은 수준으로 나타났다. 2배 증폭된 경우, 검증 손실이 0.95에서 시작하여 50 epoch 이후 0.1 이하로 감소하였으며, 학습 손실도 0.9에서 시작하여 0.05 이하로 수렴하였다. 3배 증폭된 경우, 초기 검증 손실이 0.9로 다소 낮아졌으며, 50 epoch 이후 0.05 이하로 감소하였다. 4배, 5배, 100배 증폭된 경우에도 유사한 패턴을 보이며, 검증 손실이 각각 0.8, 0.7, 0.6에서 시작하여 0.01 이하로 감소하였다. 특히, 100배 증폭된 경우, 20 epoch 이후 급격한 검증 손실 감소가 분석되었다.
CTGAN 기법을 적용한 경우, 다른 기법들과 비교했을 때 초기 학습 손실 및 검증 손실이 상대적으로 낮은 수준에서 시작하였다. 이는 CTGAN이 원본 데이터의 분포를 효과적으로 학습하여 새로운 데이터를 생성했기 때문으로 해석된다. 2배 증폭된 경우, 검증 손실이 0.7에서 시작하여 40 epoch 이후 0.1 이하로 수렴하였으며, 학습 손실은 0.65에서 시작하여 0.05 이하로 감소하였다. 3배로 증폭된 경우, 검증 손실이 0.65에서 시작하여 30 epoch 이후 0.05 이하로 급격히 감소하였다. 4배, 5배 증폭된 경우, 검증 손실은 0.6에서 0.02까지 감소하였고, 100배 증폭된 경우에는 검증 손실이 0.5에서 시작하여 10 epoch 이후 0.01 이하로 가장 빠르게 수렴하였다.
각 오버샘플링 기법에 따른 DNN 학습 결과를 종합적으로 분석한 결과, 모든 기법에서 데이터 증폭 배수가 증가함에 따라 검증 손실과 학습 손실이 빠르게 감소하고, 최종적으로 낮은 손실 수준에서 수렴하는 경향이 나타났다. SMOTE, Borderline-SMOTE, ADASYN 기법은 학습 초기 손실이 다소 높게 나타났으나, 데이터 증폭 배수에 따라 안정적으로 학습 손실과 검증 손실이 감소하였다. 반면, CTGAN 기법은 학습 초기부터 낮은 손실 값으로 시작하여, 데이터 증폭 효과가 극대화되며 가장 빠르게 수렴하였다. 이러한 결과는 CTGAN이 다른 오버샘플링 기법에 비해 예측 모델의 초기 학습 성능을 향상시키고, 데이터 분포의 균형을 효과적으로 유지하는 데 유리함을 의미한다.
3.2.2 예측 모델의 신뢰성 검증
다양한 오버샘플링 기법을 적용하여 DNN 모델의 예측 성능을 평가하기 위해 테스트 손실(Test Loss) 및 테스트 평균제곱오차(Test MSE)를 분석하였다. 오버샘플링 ×2, ×3, ×4, ×5 그리고 ×100로 증폭된 데이터를 기반으로 DNN 알고리즘을 적용한 후의 예측 성능 결과를 Fig. 7에 나타내었다. 평균 테스트 손실은 모델이 학습 후 검증 데이터에 대해 예측한 평균적인 오차를 나타내며, 평균 테스트 MSE는 예측값과 실제값 간의 평균 제곱 오차로 모델의 예측 정확도를 정량적으로 평가하는 데 사용된다.
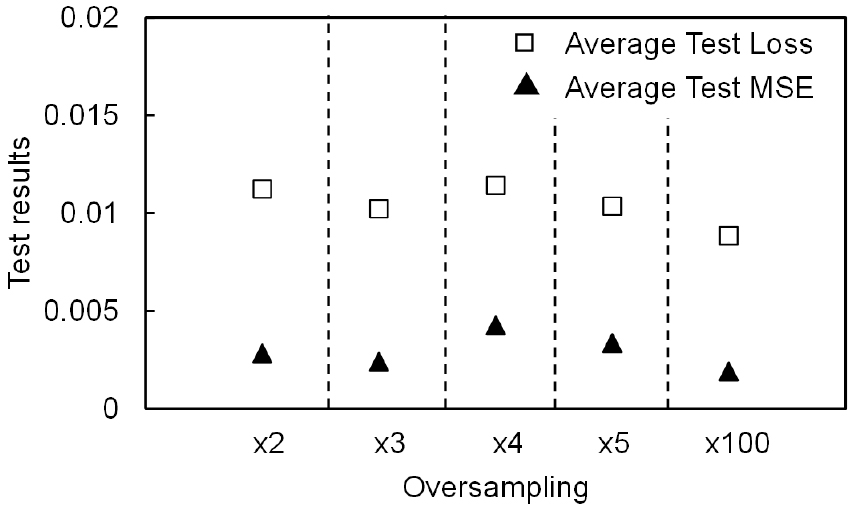
평균 테스트 손실은 오버샘플링을 통해 증폭된 데이터의 양에 따라 변동을 보이며 전반적으로 감소하는 경향을 나타냈다. 데이터가 2배로 증폭된 경우 평균 테스트 손실은 0.0112로 측정되었으며, 3배 증폭 시 0.0102로 감소하였다. 이는 데이터양이 증가함에 따라 모델이 더 다양한 학습 데이터를 접할 수 있게 되어 예측 성능이 개선되었음을 의미한다. 그러나 4배 증폭 시 평균 테스트 손실이 0.0114로 증가하는 현상이 관찰되었으며, 이는 생성된 데이터의 품질이 낮거나 학습 데이터의 불균형으로 인해 모델 성능이 다소 저하되었을 가능성을 시사한다. 이후 5배 증폭 시 손실이 0.0104로 다시 감소하는 양상을 보였으며, 100배 증폭된 데이터에서는 0.0088로 가장 낮은 값을 기록하였다. 이는 대규모 데이터 증폭이 모델의 학습 데이터 다양성을 증가시키고, 예측 성능을 향상시키는 데 긍정적인 영향을 미쳤음을 의미한다.
평균 테스트 MSE(Mean Squared Error) 역시 데이터 증폭 배수에 따라 유사한 변화를 보였다. 2배 증폭된 데이터의 경우 평균 MSE는 0.0028을 기록하였으며, 3배 증폭 시 0.0024로 감소하여 예측 성능이 향상되었다. 그러나 4배 증폭 시 0.0043으로 증가하는 경향이 나타났으며, 이는 모델이 증폭된 데이터에서 학습하는 과정에서 일부 데이터의 품질이 저하되었을 가능성을 의미한다. 5배 증폭된 경우 평균 MSE는 0.0034로 다시 감소하였으며, 100배 증폭된 경우 0.0019로 최젓값을 기록하였다. 이는 데이터 증폭이 충분히 이루어질 경우 모델이 보다 다양한 데이터 패턴을 학습할 수 있어 예측 정확도가 높아진다는 점을 시사한다.
이러한 결과를 종합해보면, 데이터 증폭이 일정 수준까지는 모델 성능 향상에 기여하지만, 증폭 배수가 증가할수록 데이터 품질 저하로 인해 성능이 일시적으로 저하될 가능성이 존재함을 알 수 있다. 따라서 모델 학습에 적절한 데이터 증폭 비율을 설정하는 것이 중요하며, 지나치게 많은 데이터를 증폭하는 경우 오히려 예측 성능을 저하시킬 수 있음을 고려해야 한다. 본 연구에서는 100배 증폭 시 가장 낮은 평균 테스트 손실과 평균 테스트 MSE를 기록하였으므로, 대규모 데이터 증폭이 모델 성능 향상에 긍정적인 영향을 미칠 수 있음을 확인하였다.
4. 결 론
본 연구에서는 지하 수소저장시설에서 발생하는 폭발이 지반 진동에 미치는 영향을 분석하고, 이를 정량적으로 예측할 수 있는 모델을 개발하였다. 이를 통해 지하 수소저장시설 폭발 시 지반 거동을 보다 정밀하게 평가하고, 향후 방호 설계 및 안전성 평가에 기여할 수 있는 기초 자료를 제시하였다. 본 연구의 주요 결론은 다음과 같다.
(1) 비선형 유한요소해석 기법을 활용하여 지하 수소저장시설 폭발에 따른 지반의 동적 거동을 분석하였다. 이를 위해 Coupled Eulerian-Lagrangian 모델과 Mohr-Coulomb 모델을 적용하여 폭발 하중에 따른 지반 거동을 정량적으로 평가하였다. 또한, 다양한 매개변수 조건(수소 농도, 토피고, 지반 조건 등)에 따른 폭발 영향을 분석하고, 총 8,066건의 이격 거리별 최대 진동치 DB를 구축하였다. 이를 통해 폭발 하중에 대한 지반의 비선형적 응답을 정량적으로 평가할 수 있는 기초 데이터를 확보하였다.
(2) AI 기반 예측 모델을 개발하여 폭발에 따른 지반 진동을 효과적으로 예측하였다. 본 연구에서는 DNN 알고리즘을 적용하였으며, 모델의 성능 최적화를 위해 데이터 증폭 및 이상치 제거 기법을 활용하였다. 특히, 데이터 부족으로 인한 모델 성능 저하를 방지하기 위해 SMOTE, Borderline-SMOTE, ADASYN, CTGAN 등의 데이터 증폭 기법을 적용하였다. 분석 결과, 데이터 증폭 배수가 증가할수록 학습 및 검증 손실이 감소하는 경향을 보였으며, 특히 100배 증폭된 데이터 셋에서 가장 낮은 테스트 손실이 나타났으며, 2배 증폭 대비 평균제곱오차(MSE)가 약 32.1 %만큼 감소하였다. 이는 대규모 데이터 증폭이 모델의 학습 데이터 다양성을 증가시키고 예측 성능을 향상시키는 데 효과적임을 시사한다.
(3) 데이터 증폭이 항상 예측 성능을 향상시키는 것은 아니며, 적절한 증폭 비율 설정이 중요함을 확인하였다. 특정 증폭 배수 이상에서는 모델의 예측 정확도가 오히려 저하될 가능성이 있으며, 특히 CTGAN을 활용한 데이터 증폭에서는 원본 데이터의 분포를 충분히 반영하지 못하는 문제가 발생하였다. 일부 데이터에서는 분포 왜곡이 발생하여 모델 학습에 부정적인 영향을 미칠 가능성이 있음이 확인되었다. 따라서 AI 기반의 지반 진동 예측 모델을 개발할 때는 데이터 증폭 방법의 선택과 적절한 매개변수 설정이 중요하며, 원본 데이터의 특성을 유지하면서 증폭된 데이터를 활용하는 것이 필요함을 확인하였다.
