

1. 서 론
2. 강화학습 기본 개념
3. Proximal Policy Optimization(PPO) 알고리즘
3.1 Proximal Policy Optimization(PPO) 알고리즘 개요
3.2 PPO 알고리즘의 특성
4. 강화학습 기반 구조 최적설계
4.1 합성보 단면 최적 설계
4.2 트러스 단면 최적 설계
5. 결 론
1. 서 론
현대 건축물은 도시화에 따른 공간 효율성 극대화를 위해 점차 대형화 및 고층화되고 있으며, 구조시스템 및 각 부재 상세가 복잡해지는 추세이다. 이러한 구조물은 자중 및 적재 하중과 같은 상시 하중뿐만 아니라 테러, 폭발, 충돌 및 예기치 못한 자연재해 등 극한 하중에 노출될 위험이 존재한다. 구조 최적화 설계는 주어진 제약 조건 내에서 재료 사용을 최소화하면서도 요구되는 성능을 극대화하는 것을 목적으로 한다. 그러나 전통적인 수치 최적화 기법은 설계 변수가 방대하고 제약 조건이 비선형성을 갖는 경우 해를 찾는 데 막대한 계산 시간이 소요되거나 국부 최적해(Local optima)에 빠지는 한계가 있다. 또한, 방호 시설과 같이 설계 데이터가 부족한 특수 목적 구조물의 경우, 기존의 사례 기반 설계 방식으로는 최적의 설계 결과를 도출하기 어려운 상황이다. 이러한 배경에서 학습 데이터 없이 규칙만으로 학습이 가능한 강화학습 모델을 통해 구조설계 최적화 기술을 개발하는 것은 구조설계 경제성 및 신뢰성, 건설 생산성 향상이 가능하다.
최근 인공지능 기술의 비약적인 발전으로 구조 공학 분야에서도 강화학습을 활용한 연구가 활발히 진행되고 있다. Zhao et al.(2026)은 Soft Actor-Critic(SAC) 알고리즘을 활용하여 철근 콘크리트(RC) 전단벽의 자동 설계를 제안하였다. 이 모델은 정답 데이터가 부족한 환경에서도 현행 설계기준을 엄격히 준수하도록 구성되었으며, 부재 재료비를 최소화하는 보상 함수를 통해 경제성을 확보하였다. 특히 100,000회의 학습 후, 0.1초 만에 최적의 설계안을 도출하는 성능을 보였다. 현행 설계기준의 공식이 복잡하거나 전단강도를 정확히 예측하기 어려운 경우를 대비하여, XGBoost와 같은 기계 학습 기법을 강화학습과 결합하는 시도가 이루어졌다. ACI 445B 데이터베이스 등 774개의 실험 데이터를 활용해 전단 강도를 예측하고, 이를 강화학습 에이전트의 판단 근거로 활용함으로써 기존 설계기준 기반 방식보다 높은 적응성과 안정성을 입증하였다. Rochefort-Beaudoin et al.(2025)은 구조적으로 견고한 설계를 생성할 수 있는 오픈 소스 강화학습 환경인 Structural Optimization gym(SOgym)을 제안하였다. 기존의 이미지 기반 지도학습 모델들이 하중 경로가 끊어진 부적절한 구조물을 생성하는 한계를 보였던 것과 달리, SOgym은 유한요소해석 결과를 보상 함수에 직접 통합하였다. 이를 통해 에이전트가 하중과 지점 사이의 연결성을 스스로 학습하게 하여, 1,000개의 무작위 테스트 케이스에서 단절률 0 %라는 높은 신뢰도의 구조설계를 구현하였다. Model-based 알고리즘인 DreamerV3를 활용하여 기존 최적화 방식에 근접한 성능을 확보하였으며, 학습 후 추론 과정이 30분 이내로 소요되어 실무 적용 가능성을 확인하였다. Lemus-Romani et al.(2023)은 옹벽 설계 시 전통적인 경험 기반 방식의 한계를 극복하기 위한 최적화 모델을 제안하였다. 이 연구는 캔틸레버 옹벽을 대상으로 비용 최소화와 이산화탄소 배출량 저감이라는 두 가지 목적 함수를 설정하고, 이를 해결하기 위해 강화학습과 메타휴리스틱 기법을 유기적으로 결합하였다. 연속적인 탐색 공간에 작용하는 메타휴리스틱 알고리즘인 Sine Cosine Algorithm(SCA), Whale Optimization Algorithm(WOA), Gray Wolf Optimization(GWO)를 이산적인 설계 문제에 효율적으로 적용하였으며, 특히 Q-Learning 및 SARSA 강화학습 기법을 활용한 지능형 이산화 체계 선택기(Discretization Schemes Selector)를 도입하여, 매 반복 과정에서 보상 시스템을 통해 최적의 전이 함수를 스스로 선택하도록 설계하였다. 이러한 방식은 알고리즘의 탐색과 활용 사이의 균형을 최적으로 유지함으로써 국부 최적해에 빠지는 것을 방지한다. 알고리즘 테스트 결과, GWO 알고리즘과 S-shaped 전이 함수를 결합한 모델이 가장 견고하고 우수한 성능을 보였으며, 31회의 독립적인 시뮬레이션과 Wilcoxon-Mann-Whitney 통계 검정을 통해 그 유의성이 입증되었다. 결과적으로 이 연구는 ACI 318-05 등 현행 설계기준의 요구조건을 준수하면서도 공사비와 탄소 배출량을 획기적으로 절감할 수 있음을 보여주었으며, 이산적 공학 문제 해결을 위한 데이터 기반의 지능형 최적화 프레임워크의 가능성을 제시하였다.
최근 강화학습을 활용한 구조 최적화 연구는 비약적인 성과를 거두고 있으나, 대다수의 연구가 ‘데이터 중심의 대리 모델(Data-driven Surrogate Model)’ 방식에 머물러 있다는 한계가 있다. 이러한 방식은 인공지능을 학습시키기 위해 사전에 수만 번의 구조 해석을 수행하여 대규모 데이터셋을 구축해야 하므로, 데이터 생성에 막대한 시간과 연산 자원이 소모된다. 또한, 구조 해석 엔진이 학습 루프 외부에 존재함에 따라 에이전트가 물리적 거동의 원리를 직접 학습하기보다는 주어진 데이터 내의 통계적 상관관계만을 모사하게 되어, 설계 조건이 변경될 경우 모델의 재사용성이 현저히 떨어진다는 문제점이 있다. 따라서 단순히 구축된 데이터를 학습하는 수준을 넘어, 구조 해석 엔진과 최적화 알고리즘이 실시간으로 상호작용하는 통합형 시스템에 대한 연구가 요구된다. 인공지능 에이전트가 물리 법칙이 내재된 환경에서 직접 시행착오를 겪으며 물리적 응답을 보상 신호로 수용할 수 있다면, 사전에 정답 데이터를 구축해야 하는 번거로움을 제거함과 동시에 설계의 신뢰도와 범용성을 획기적으로 높일 수 있다.
본 연구는 이러한 데이터 의존성 문제를 해결하기 위해, 구조 해석 엔진을 강화학습의 환경 내부에 직접 통합하였다. 사전에 구축된 데이터셋에 의존하는 대신, 에이전트가 매 스텝마다 구조 해석 엔진과 실시간으로 상호작용하며 스스로 물리적 거동을 파악한다. 이는 별도의 데이터 구축 공정 없이도 최적 설계를 가능하게 한다. 해석 모듈이 시스템 내부에 내재화되어 있으므로, 부재의 형상이나 설계 제한 조건이 변경되더라도 추가적인 데이터 생성 없이 즉각적으로 최적화 프로세스를 수행할 수 있는 유연성을 확보하였다. 이는 데이터 확보의 한계를 극복함과 동시에, 물리적 거동 특성을 학습 프로세스에 직접 반영하여 공학적 타당성이 확보된 설계안을 자율적으로 도출한다는 점에서 기존 연구와 차별화되는 독창성을 갖는다. 이러한 해석-학습 통합 시스템의 기술적 이점을 구체화하기 위해, 본 연구에서는 강화학습 알고리즘을 활용하여 구조물의 안전성을 극대화하고 재료 효율성을 최적화하는 범용적인 설계 프레임워크를 제안한다. 특히, 극한 하중 하에서 시설물의 저항 성능을 높이기 위해 변위 및 부재력을 효과적으로 제어할 수 있는 학습 모델을 구축한다. 이를 위해 OpenAI Gymnasium 프레임워크를 기반으로 구조 해석 엔진이 연동된 사용자 정의 환경을 구축하고, 합성보 단면 최적화와 트러스 설계의 두 가지 핵심 예제를 통해 그 유효성을 검증한다.
2. 강화학습 기본 개념
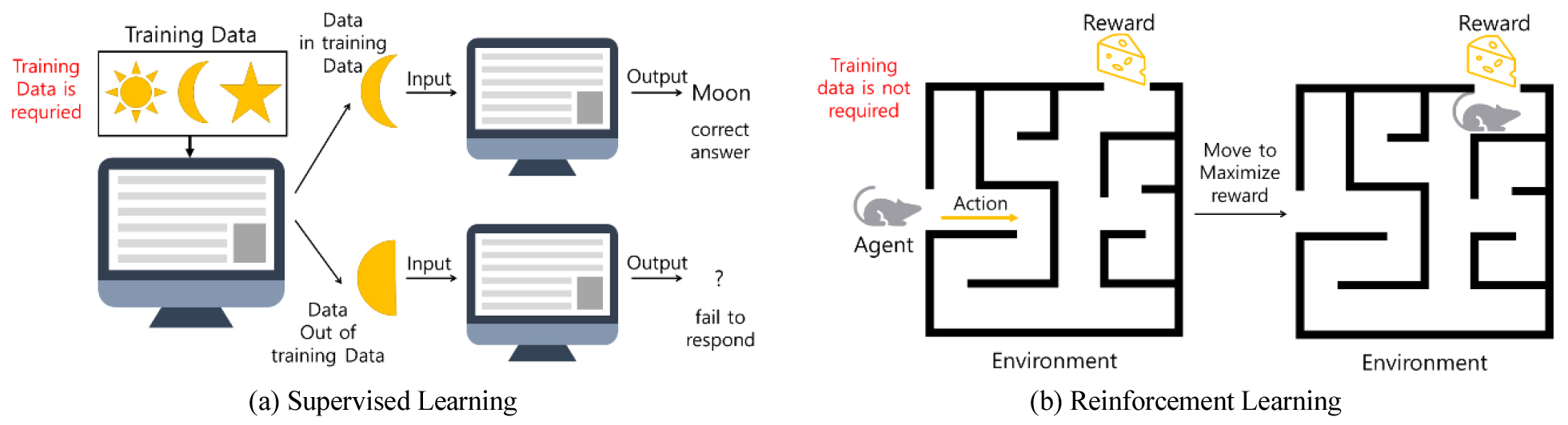
강화학습(Sutton and Barto, 2018)은 정의된 환경 내에서 의사결정 주체인 에이전트가 특정 행동을 취하고, 그 결과로 변화된 상태와 보상을 주고받으며 학습하는 기계학습의 한 분야로 에이전트가 현재 상태를 바탕으로 누적 보상을 최대화하는 행동을 스스로 선택하도록 한다. Fig. 1(a)에 나타난 바와 같이 지도학습이 정답(Label)이 포함된 대규모 데이터를 학습하여 결과에 대한 예측 모델을 형성하는 방식이라면, Fig. 1(b)에서 확인할 수 있는 강화학습은 별도의 학습 데이터 없이 환경과의 능동적인 상호작용 및 시행착오를 통해 누적 보상을 최대화하는 정책을 자율적으로 수립한다는 점에서 근본적인 차별성을 갖는다.
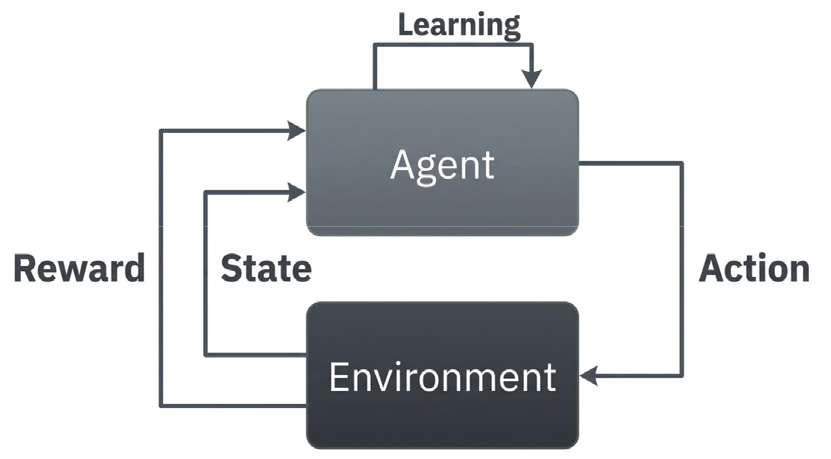
강화학습 모델은 크게 환경(Environment)과 에이전트(Agent), 그리고 이들의 상호작용을 정의하는 상태(State), 행동(Action), 보상(Reward)으로 구성된다. 환경은 에이전트의 행동에 반응하여 결과와 보상을 생성하는 모든 외적 요소를 포함하며, 해결해야 할 문제를 에이전트에게 제시한다. 에이전트는 환경 속에서 학습을 수행하는 주체이자 의사결정을 내리는 개체로, 환경과의 지속적인 상호작용을 통해 최적의 설계 정책을 수립한다. 상태는 특정 시점에 에이전트가 처한 환경을 수치적으로 표현한 정보의 집합이자, 의사결정을 위한 기초 데이터를 의미한다. 에이전트는 환경으로부터 전달받은 상태를 관측함으로써 현재의 상황을 인식하고, 이를 바탕으로 보상을 극대화할 수 있는 최적의 행동을 결정한다. 일반적으로 상태는 에이전트의 위치나 속도와 같은 동적 데이터뿐만 아니라, 주변 환경의 구성이나 기하학적 배치와 같은 정적 데이터를 모두 포함할 수 있다. 에이전트가 특정 상태에서 취하는 물리적 행위인 행동은 초기에는 정보 부족으로 인해 무작위로 선택되나, 학습이 반복됨에 따라 보상을 극대화할 수 있는 유효한 행동의 선택 확률을 높여간다. 보상은 에이전트가 자신의 행동을 평가할 수 있는 유일한 정보원이자 학습의 지표이다. 에이전트는 누적 보상을 최대화하는 방향으로 행동을 교정하며, 연구자는 보상 값을 양수 또는 음수로 적절히 설정함으로써 에이전트가 최적해로 나아가도록 유도한다. Fig. 2에 제시된 강화학습 상호작용 루프는 이러한 구성 요소 간의 순환적인 정보 흐름을 보여준다. 그림에 나타난 바와 같이, 강화학습은 매 시간 단계 t에서 시행착오(Trial-and-error) 과정을 반복한다.
3. Proximal Policy Optimization(PPO) 알고리즘
3.1 Proximal Policy Optimization(PPO) 알고리즘 개요
Proximal Policy Optimization(PPO) 알고리즘(Schulman et al., 2017)은 Trust Region Policy Optimization(TRPO)(Schulman et al., 2015)의 수학적 근간을 유지하면서도 계산적 복잡성을 획기적으로 개선한 알고리즘이다. TRPO는 정책 함수의 성능 향상을 보장하기 위해 기대 보상 합의 하한선인 식 (1)의 목적 함수 L을 최대화하는 정책 를 탐색한다. 이때 학습에 적합한 크기(Step size)를 만족하는 영역을 신뢰 영역(Trust Region)으로 정의하며, 정책 업데이트가 이 영역 내에서 이루어지도록 제한한다. 그러나 TRPO는 신뢰 영역 내에서의 최적 정책을 찾기 위해 모든 상태에 대한 KL 발산(Kullback-Leibler Divergence)의 헤시안(Hessian) 행렬, 즉 2차 미분값을 계산해야 하는 한계가 있다. 이는 대규모 상태 공간을 가진 실제 공학 문제에서 계산 비용을 기하급수적으로 증가시키며 구현의 난이도를 높이는 원인이 된다.
식 (1)에서 π는 에이전트의 설계 정책(Policy), 는 이전 정책 대비 성능 향상도를 나타내는 대리 목적 함수(Surrogate objective)를 의미한다. 또한, 와 δ는 각각 정책 업데이트 시 발생하는 확률 분포의 차이와 이를 제한하기 위한 신뢰 영역(Trust region)의 임계치를 나타내며, 와 는 각각 이전과 현재 정책의 파라미터를 의미한다.
PPO는 TRPO의 복잡한 제약 조건을 Clipping 기법(Schulman et al., 2017)으로 대체함으로써 1차 미분만으로도 목적 함수의 근사가 가능하도록 설계되었다. PPO의 최종 목적 함수는 식 (2)와 같이 크게 세 가지 요소(대리 목적 함수, 가치 함수 손실, 엔트로피 보너스)의 결합으로 구성된다.
여기서 은 이전 정책과 현재 정책의 비율을 일정 범위 내로 제한하여 정책의 급격한 변화를 방지하며, 는 제곱 오차 손실(Mean Squared Error)을 통해 가치 함수의 정확도를 높인다. 또한 엔트로피 보너스는 에이전트가 충분한 탐색을 지속하도록 유도하는 역할을 하며, 과 는 각 항의 가중치를 조절하는 계수이다.
3.2 PPO 알고리즘의 특성
PPO 알고리즘은 최적화 모델 구축에 적합하며, 이는 다음과 같은 특징에 기반한다. 1) PPO는 다수의 Actor가 병렬적으로 데이터를 수집하고 그 평균치를 바탕으로 학습을 진행함으로써 샘플 효율성을 높인다. 2) 특히 Clipping 메커니즘을 통해 수집된 데이터를 안정적으로 여러 번 재사용할 수 있어 학습 속도가 빠르고 수렴성이 우수하다는 장점이 있다. 3) PPO는 연속적 행동 제어 능력이 매우 탁월하여, 합성보 설계나 트러스 단면 최적화와 같이 다수의 설계 변수를 동시에 연속적인 수치로 미세하게 조정해야 하는 환경에서 독보적인 성능을 발휘한다. 4) TRPO와 비교했을 때 알고리즘 구조가 상대적으로 간결하여 파이썬 기반의 오픈소스 라이브러리를 통한 구현 용이성이 높으며, 다양한 하이퍼파라미터 설정 환경에서도 학습 곡선이 급격하게 요동치지 않고 안정적으로 수렴한다는 강점이 있다. 이러한 특징은 설계 변수들이 서로 밀접하게 결합된 구조 시스템의 다변수 연계 최적화에 매우 적합하다. PPO는 정책의 급격한 변화를 억제하는 메커니즘을 갖추고 있어, 미세한 설계 변경이 전체 시스템 거동에 민감하게 작용하는 환경에서도 비교적 일관된 학습 방향을 유지한다. 이를 통해 에이전트는 변수 간의 복잡한 상호작용을 정밀하게 학습하여, 극한 하중 하에서도 신뢰도가 보장된 자율 설계 정책을 수립하는 데 핵심적인 역할을 한다.
4. 강화학습 기반 구조 최적설계
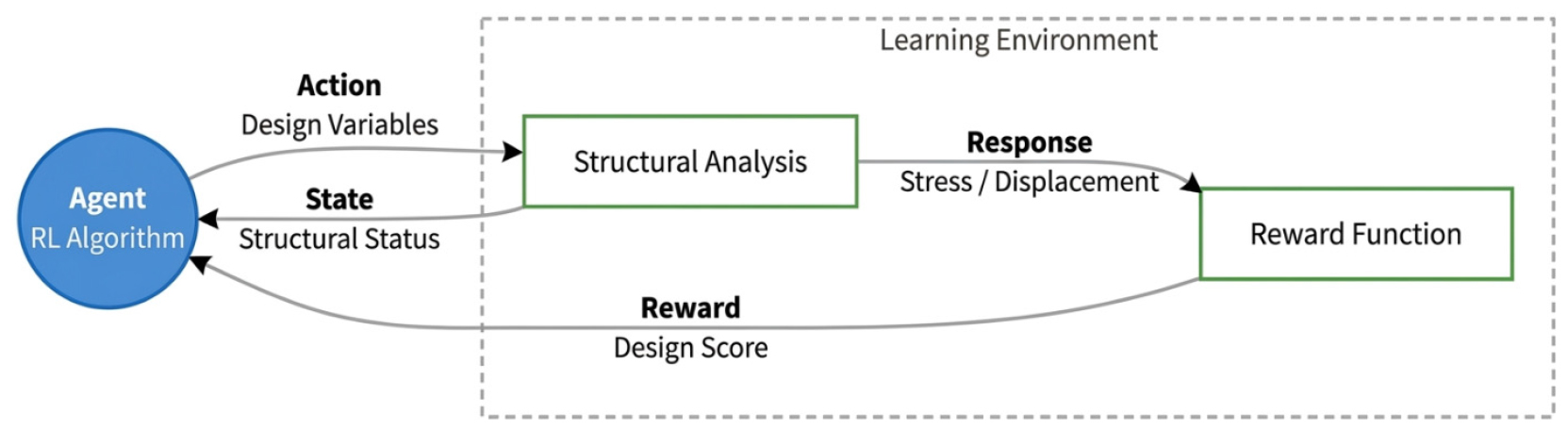
강화학습 프레임워크의 구조 최적화 성능과 유효성을 검증하기 위해 합성보 단면 및 트러스 구조 설계에 적용하였다. 각 설계모델은 파이썬 기반의 Gymnasium 라이브러리(Towers et al., 2024)를 통해 환경을 구축하였으며, Stable-Baselines3(Raffin et al., 2021)에서 제공하는 PPO 알고리즘을 활용하여 학습을 진행하였다. 학습환경은 Fig. 3과 같은 순서로 진행된다. 에이전트와 구조 해석 엔진 간의 유기적인 상호작용을 통해 최적의 설계안을 자율적으로 도출하는 시스템이다. 에이전트가 제안한 설계 변수는 실시간 구조해석을 통해 물리적 타당성을 검증받으며, 도출된 구조 거동에 따라 안전성과 경제성이 통합된 보상이 부여된다. 이러한 반복 학습 프로세스를 통해 시스템은 복잡한 최적화 기법을 적용하지 않아도 공학적 판단 기준을 만족하는 최적 설계 정책을 스스로 수립하게 된다.
4.1 합성보 단면 최적 설계
충전형 U형 강재 합성보(Kim et al., 2018)는 일반 강재 보에 비해 설계 변수가 다양하고, 콘크리트와 강재의 합성 거동에 따른 단면 계산 과정이 복잡하다. 이로 인해 설계자가 경제성과 안전성을 모두 만족하는 최적의 단면 치수를 수작업으로 도출하는 데에는 많은 시간과 노력이 소요되는 한계가 있다. 따라서 방대한 설계 공간 내에서 최적의 조합을 신속하고 정밀하게 탐색할 수 있는 자동화된 설계 기법의 도입이 요구된다. 이에 본 연구에서 강화학습 프레임워크를 구축하여 Fig. 4와 같은 충전형 U형 강재 합성보의 단면 최적화를 수행하였다. U형 합성보 단면 설계시 슬래브 두께 200 mm, 콘크리트강도 30 MPa, 강재 항복강도 355 MPa, 강재 탄성계수 210000 MPa을 고려하였다. 슬래브는 평데크 슬래브로 D13 철근 15개를 배근하였으며 피복 두께는 40 mm, 유효폭은 2000 mm로 고정하였다. 보의 양 끝단은 고정단으로 보의 내부 철근에 대해서는 고려하지 않았다.
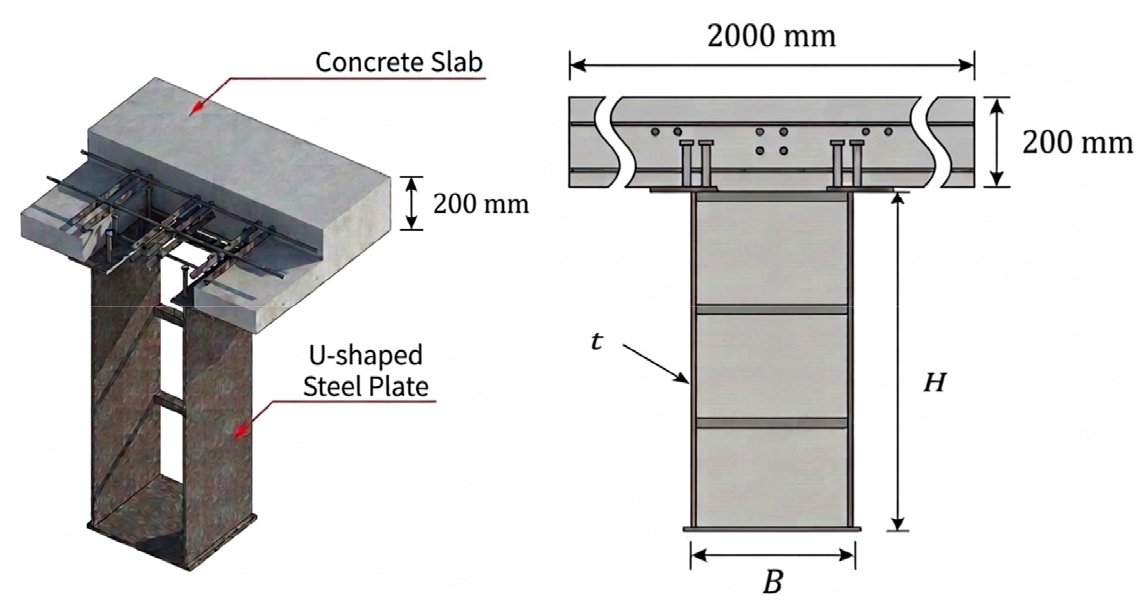
보 단면의 공칭휨강도는 건축물 강합성구조 설계기준(KDS 41 30 20; MOLIT, 2022)에 따라 소성응력분포법으로 산정하였다. 본 연구에서는 전단연결재가 충분히 배치되어 강판과 내부콘크리트의 완전합성(Full Composite) 상태를 가정하였다. 휨을 받는 충전형 합성부재의 국부좌굴 영향을 반영하기 위해, 압축 연단에 위치한 강재 요소의 판폭두께비를 기준으로 단면을 조밀(Compact), 비조밀(Non-compact), 세장(Slender) 단면으로 분류하였다. 강화학습 에이전트가 결정한 단면 치수가 속한 조건에 따라 휨강도 산정 방식을 다음과 같이 차등 적용하여 물리적 타당성을 확보하였다. 1) 조밀 단면: 소성응력분포법에 근거한 소성모멘트강도 적용; 2) 비조밀 단면: 판폭두께비에 따라 소성모멘트와 항복모멘트를 선형보간하여 산정; 3) 세장 단면: 정모멘트 작용 시에는 항복모멘트를, 부모멘트 작용 시에는 좌굴모멘트를 공칭휨강도로 채택하여 국부좌굴에 의한 강도 저하를 반영. 이러한 설계기준을 환경 로직에 통합함으로써, 학습 과정에서 에이전트가 판폭두께비 제한과 같은 공학적 제약 조건을 만족하면서도 요구 모멘트에 대해 최적의 재료 효율을 갖는 단면 치수를 자율적으로 탐색할 수 있도록 설계되었다.
U형 합성보 단면 최적화를 위한 강화학습 환경은 다음과 같이 정의하였다. 행동(Action) 공간은 U형 합성보의 주요 기하학적 변수인 춤(d), 폭(w), 두께(t)를 설계 변수로 설정하여 정의하였다. 에이전트는 각 학습 단계에서 단면 치수를 –10 mm에서 +10 mm 사이의 정수 범위 내에서 최적 형상을 탐색한다. 이때, 두께(t) 변수는 0.5 mm 단위로 제어하였다. 상태(State) 정보로는 변화된 단면 치수에 따른 구조해석 결과를 에이전트에게 실시간으로 제공하였다. 여기에는 U형 합성보 단면의 공칭 휨강도(Nominal Moment Capacity)와 강재비 등 구조적 효율성과 안전성을 판단할 수 있는 핵심 지표들이 포함된다. 최적화 목표는 기존 기성 제품(526×300×6)의 성능 수준을 상회하는 것을 기준으로 하였다. 이에 따라 요구 성능을 정모멘트 1,221.3 kN·m, 부모멘트 891.0 kN·m로 설정하여 에이전트가 해당 설계 하중을 만족하면서도 최적의 단면 효율을 찾도록 유도하였다. 모델의 안정적인 수렴과 최적해 도출을 위해 총 100,000 에피소드 동안 학습을 수행하였다. 에이전트가 요구 성능을 만족하면서 최소한의 물량을 갖는 단면을 도출하도록 다목적 보상 함수를 식 (3)과 같이 설계하였다(Fig. 5(a)). 특히, 강재비가 작아질수록 보상이 지수적으로 증가하도록 설정하여 경제성에 높은 가중치를 부여하였다.
여기서 은 강재비, 과 은 각각 요구 정/부모멘트에 대한 공칭휨강도의 비를 의미한다. 만약 단면 강도가 요구모멘트에 미달할 경우 패널티(음수 보상)를 부여하여 설계 제한 조건을 엄격히 준수하도록 유도하였다.
Fig. 5(b)는 총 100,000 에피소드 동안 진행된 PPO 알고리즘의 에피소드별 평균 보상을 나타낸다. 학습 후반부로 갈수록 그래프의 진폭이 줄어들며 일정한 구간 내로 수렴하는 양상을 보인다. 학습 과정 중 기록된 최고 점수는 86.3점으로, 이는 기성 단면(Reference Section)의 보상값인 79.2점을 상회하는 수치이다. 학습 후반부의 평균 점수는 최고점의 약 80 % 수준인 69.3점 부근에서 안정적으로 형성되었다. 에이전트가 학습하는 것은 단일 설계값이 아니라 최적해를 중심으로 한 확률 분포의 파라미터이다. 학습 후반부의 평균 보상은 이 분포의 기댓값(Expected Value)을 의미하며, 최고 보상은 확률적 샘플링 과정에서 발생한 최상의 사례(Best Practice)를 의미한다. 평균치가 최고점의 80 % 이상에서 안정화된 것은 학습 프로세스의 높은 안정성을 입증한다.
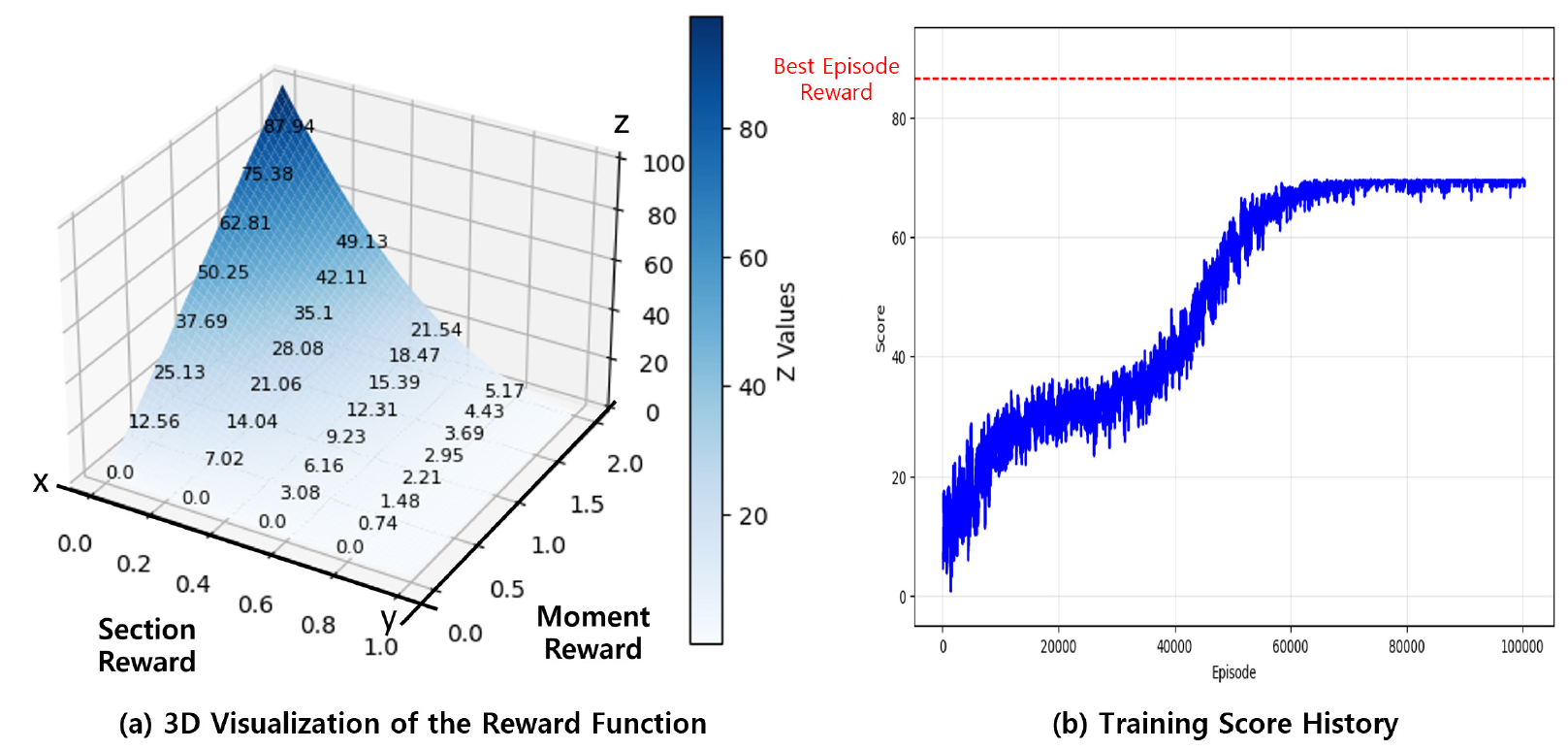
Table 1에 제시된 바와 같이, 강화학습(RL) 에이전트는 전통적인 메타휴리스틱 기법인 유전알고리즘(GA)보다 우수한 최적화 성능을 입증하였다. 기존 기성 단면(Reference Section) 대비 GA 모델은 보의 폭과 강재 두께를 유지한 채 춤만을 526.0 mm에서 500.0 mm로 축소하였으나, 강재비는 0.059로 기성 단면과 동일하여 실질적인 재료 절감 효과를 거두지 못하였다. 반면, 제안된 강화학습 에이전트는 보의 춤을 485.0 mm로 대폭 축소하는 대신 폭을 320.0 mm로 확장하는 보다 유연한 기하학적 형상 탐색을 수행하였다. 이러한 최적 단면은 기성 단면 및 GA 모델 대비 강재비를 0.057로 감소시켜 약 3.4 %의 전체 강재 사용량 절감 성과를 거두었다. 동시에 구조적 안전성 지표인 정모멘트 및 부모멘트 비에서도 GA 모델(0.98, 0.93)보다 한층 요구 성능 제한선에 근접한 0.99와 0.94를 산출해 내며 재료의 내력을 극한까지 활용하는 거동을 보였다. 결과적으로 최종 보상 점수 측면에서 RL 모델은 86.3점을 기록하여 기성 단면(79.2점)은 물론 GA 모델(84.3점)의 탐색 결과를 상회하였다. 이는 제안된 강화학습 알고리즘이 기존 수치 최적화 기법보다 구조적 안전성과 경제성(재료 물량 최소화)을 모두 만족시키는 더 높은 수준의 설계 지능을 갖추었음을 시사한다.
Table 1
Training results for composite beam section optimization
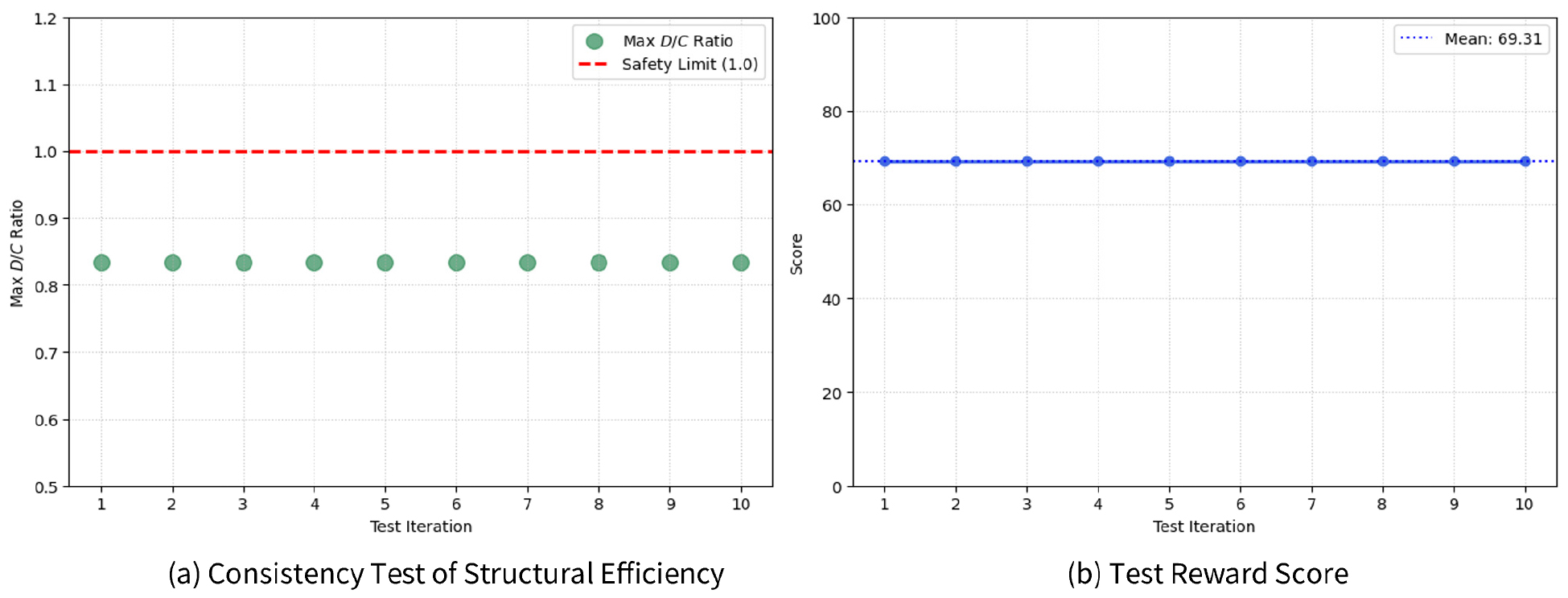
Fig. 6은 학습이 완료된 강화학습 모델의 설계 신뢰성을 평가하기 위해, 동일한 설계 하중 조건에서 10회의 독립적인 테스트를 수행한 결과를 보여준다. Fig. 6(a)는 각 테스트 차수별 최대 강도비(Max D/C Ratio)를 나타내며, 붉은 점선은 구조적 안전 한계치인 1.0을 나타낸다. Fig. 6(b)는 각 설계안에 대해 부여된 최종 보상 점수의 분포를 보여준다. 분석 결과, 10회의 반복 테스트에서 모든 설계안이 최대 강도비 0.83과 보상 점수 69.3을 오차 없이 일관되게 도출하였다. 이는 제안된 모델이 결정론적(Deterministic) 환경에서 최적 설계 해에 완벽하게 수렴하였음을 의미한다. 특히, 강도비가 안전 한계치(1.0) 이하인 0.83 수준에서 일정하게 유지되는 것은 모델이 구조적 안전성을 최우선으로 확보하면서도, 최적의 단면 효율을 찾아내고 있음을 입증한다. 이러한 결과는 AI 기반의 구조설계 프레임워크가 설계 조건이 동일할 때 항상 일관된 설계안을 도출할 수 있음을 보여주며, 이는 실무 적용에 필수적인 결과의 안정성을 확보하고 있음을 입증한다.
4.2 트러스 단면 최적 설계
트러스 구조물은 각 부재가 축력만을 부담하는 효율적인 시스템이지만, 부재 수가 증가함에 따라 각 요소의 응력 상태와 전체 물량 간의 상관관계를 고려하여 최적의 단면 조합을 도출하는 과정은 매우 복잡한 탐색 공간을 형성한다. 특히 정정 트러스(Statically Determinate Truss)는 반력과 부재력이 평형 방정식만으로 유일하게 결정되어 하중 경로가 명확하므로, 개발된 강화학습 알고리즘의 최적화 유효성을 검증하고 구조적 타당성을 확인하기 위한 기초 연구 모델로 적합하다. 이에 본 연구에서는 정정 트러스를 대상으로 강화학습 프레임워크를 우선 구축하여 알고리즘의 수렴 특성을 분석하였다.
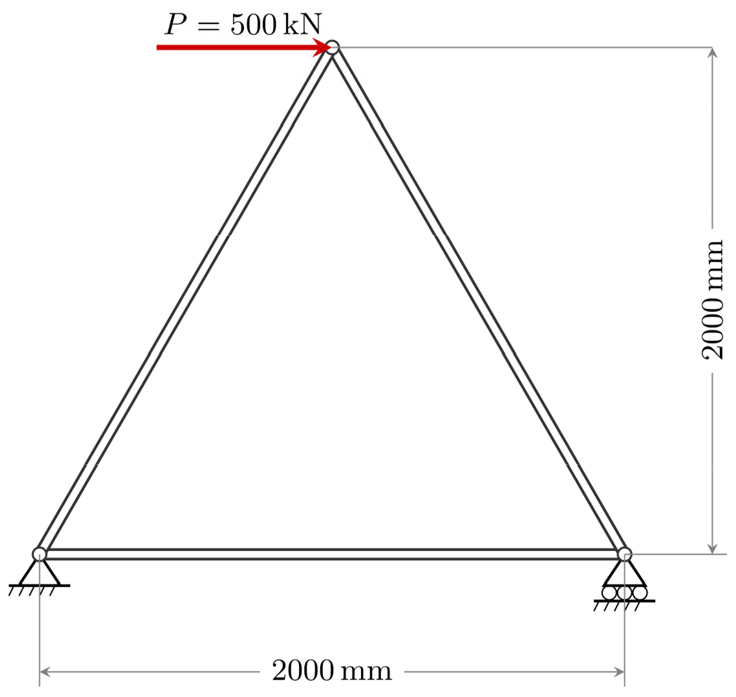
Fig. 7은 본 연구에서 사용된 2차원 3부재 정정 트러스 모델의 형상과 경계 조건을 보여준다. 재료의 탄성계수는 200,000 MPa로 설정하였으며, 에이전트가 각 부재의 단면적을 최소 200 mm2에서 최대 3,000 mm2 범위 내에서 결정하도록 행동 공간(Action Space)을 설계하였다. 구조 해석 및 상태 평가를 위해 매트릭스 변위법(Matrix Displacement Method) 기반의 솔버를 환경 로직에 통합하였다. 각 단계마다 도출된 단면적을 바탕으로 전체 강성 행렬을 구성하고 부재별 축응력을 산출하였으며, 구조적 안전성을 확보하기 위해 허용 응력을 325 MPa로 제한하였다. 강화학습 에이전트는 식 (4)와 같은 보상 체계를 통해 물리적 타당성을 학습한다.
여기서 p는 정규화된 체적을 의미하며, 트러스 구조물의 전체 체적을 설계 공간의 상한 체적으로 나누어 산정하였다. 보상 함수 내에서 (1-p)항은 에이전트가 구조적 안전성을 만족하는 범위 내에서 최소한의 물량으로 설계를 수행하도록 유도하는 경제성 지표로 작용한다. 또한, 는 부재별 응력비()를 의미하며, 은 재료의 허용 응력, 은 각 부재에 발생하는 응력을 의미한다. 부재별 상태에 따른 패널티 함수 는 식 (5)와 같이 조건부 지수 함수로 정의하여 제약 조건 위반 여부에 따른 보상의 연속성을 확보하였다.
식 (5)에서 응력비가 1.0 이하인 안전 구간에서는 응력비의 제곱에 비례하는 보상을 부여함으로써 재료의 이용 효율을 극대화하도록 유도하였다. 반면, 응력비가 1.0을 초과하는 제약 조건 위반 구간에서는 지수 감쇠 함수를 적용하여 보상을 급격히 감소시켰다. 패널티의 강도를 결정하는 상수의 값은 반복적인 시행착오를 거쳐 에이전트의 탐색 효율과 수렴 안정성을 모두 만족하는 최적 수치인 30으로 설정하였다.
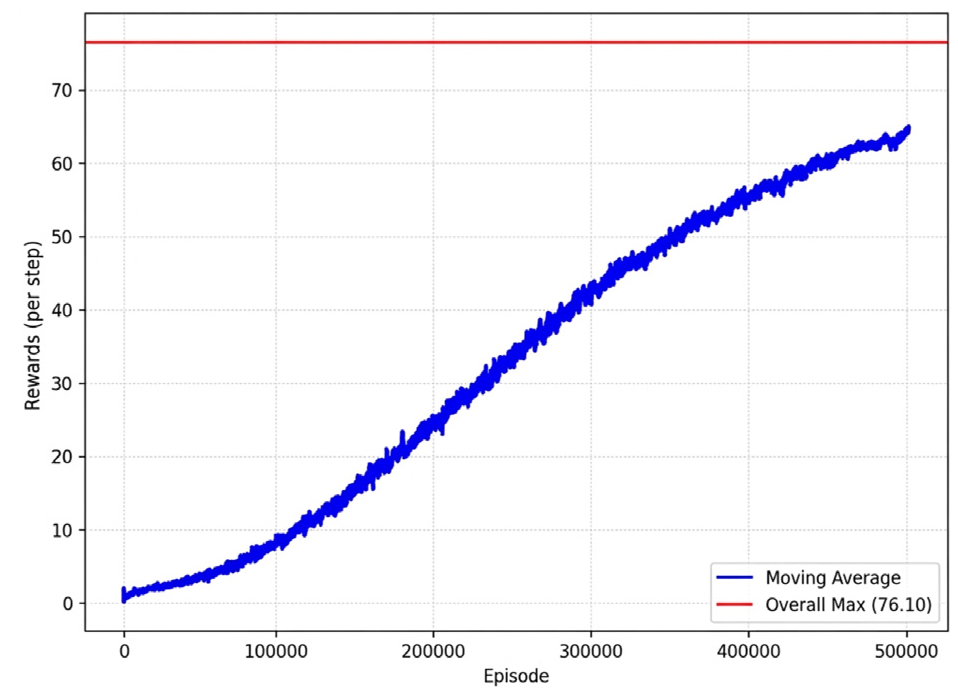
Fig. 8은 본 연구에서 제안한 PPO 기반 정정 트러스 최적화 모델의 총 500,000 에피소드 동안 학습을 수행한 학습 수렴 곡선을 나타낸다. 학습 전체 과정에서 기록된 최고 보상은 76.1이며, 에피소드 평균은 학습 후반부에서 해당 최고치의 약 80 % 수준인 60 이상에서 수렴하였다.
본 연구에서 제안한 강화학습(PPO) 기반의 최적 설계 모델과 메타휴리스틱 최적화 기법인 유전알고리즘(GA)의 결과 비교는 Table 2와 같다. 제안된 강화학습 모델은 메타휴리스틱 최적화 기법인 유전알고리즘과 비교하여 구조적 안전성을 유지하면서도 더욱 정밀한 최적 설계안을 산출하였다. GA 모델은 부재 단면적 A1, A2를 1730.0 mm2, A3를 780.0 mm2로 도출한 반면, RL 모델은 이를 각각 1722.0 mm2, 770.0 mm2로 감소시켜 추가적인 구조 경량화를 달성하였다. 두 기법 모두 하중 경로에 따라 상대적으로 큰 내력이 발생하는 A1, A2 부재의 단면적을 크게 가져가고, 내력이 작은 A3를 최소화하는 경향을 동일하게 보였다. 특히, 구조물의 기하학적 및 하중 대칭성을 반영하여 A1과 A2를 동일한 단면적으로 설계한 점은, 강화학습 에이전트가 명시적인 대칭 조건을 부여받지 않았음에도 불구하고 환경과의 반복적인 상호작용을 통해 트러스의 역학적 대칭 거동을 스스로 파악했음을 시사한다. 응력 측면에서 두 모델 모두 최대 응력비 0.99를 기록하여 허용 응력 제한치를 엄격히 준수하였다. 그러나 최대 발생 응력을 살펴보면 GA는 323.1 MPa에 머무른 반면, RL 모델은 324.6 MPa을 기록하였다. 이는 RL 에이전트가 복잡한 비선형 탐색 공간 내에서 제약 조건의 경계면에 더욱 밀접하게 접근하며, 부재의 잉여 내력을 최소화하는 방향으로 탐색을 고도화했음을 의미한다. 결과적으로 최종 보상 점수 또한 RL이 76.1점을 획득하여 GA의 72.9점 대비 우수한 수치를 나타냈다. 이를 통해 제안된 PPO 기반의 강화학습 프레임워크가 전통적인 GA 기법보다 극한의 전역 최적해(Global Optimum)를 탐색하는 데 있어 더 높은 해상도와 성능을 발휘할 수 있음을 확인하였다.
Table 2
Training results for truss section optimization
| Category | A1 (mm2) | A2 (mm2) | A3 (mm2) | Max Stress (MPa) | Max Stress Ratio | Reward |
| GA Optimized Section | 1730.0 | 1730.0 | 780.0 | 323.1 | 0.99 | 72.9 |
| RL Optimized Section | 1722.0 | 1722.0 | 770.0 | 324.6 | 0.99 | 76.1 |
학습이 완료된 PPO 기반 구조 최적화 모델의 추론 성능의 신뢰성을 검증하기 위해, 동일한 하중 및 경계 조건 하에서 10회의 독립적인 반복 테스트를 수행하였다. Fig. 9는 10회 반복 테스트에 따른 구조 효율성 지표와 보상 점수의 변동성을 나타낸다. Fig. 9(a)에서 보듯이, 10회의 테스트 동안 모델이 산출한 모든 설계안의 최대 응력비가 안전 한계선(Safety Limit, 1.0)을 위반하지 않고 약 0.98 수준을 유지하는 것을 확인할 수 있다. 이는 제안된 에이전트가 단면적을 무작위로 축소하는 것이 아니라, 구조적 제약 조건을 엄격하게 준수하면서도 잉여 내력을 최소화하는 ‘극한의 설계 경계면’을 일관되게 탐색해 내는 능력을 갖추었음을 의미한다. 또한, Fig. 9(b)의 테스트 보상 점수 분포를 통해 알고리즘의 수렴 안정성을 교차 검증하였다. 10회의 에피소드 동안 획득한 보상 점수는 평균 67.96점으로, 표준편차가 거의 0에 수렴하는 일관성을 보였다. 이는 앞서 제안한 조건부 지수 형태의 소프트 제약(Soft Constraint) 보상 함수가 에이전트의 학습 방향을 성공적으로 유도하였으며, 최종적으로 도출된 정책(Policy)이 확률적 노이즈(Stochastic Noise)에 흔들리지 않고 전역 최적해로 수렴하였음을 의미한다. 결과적으로 본 연구에서 제안한 PPO 기반 트러스 최적화 프레임워크는 단순히 단발성의 최적해를 찾는 것을 넘어, 반복적인 설계 환경에서도 변동성 없이 안전하고 경제적인 단면을 도출할 수 있는 신뢰성을 확보하였음을 확인하였다.
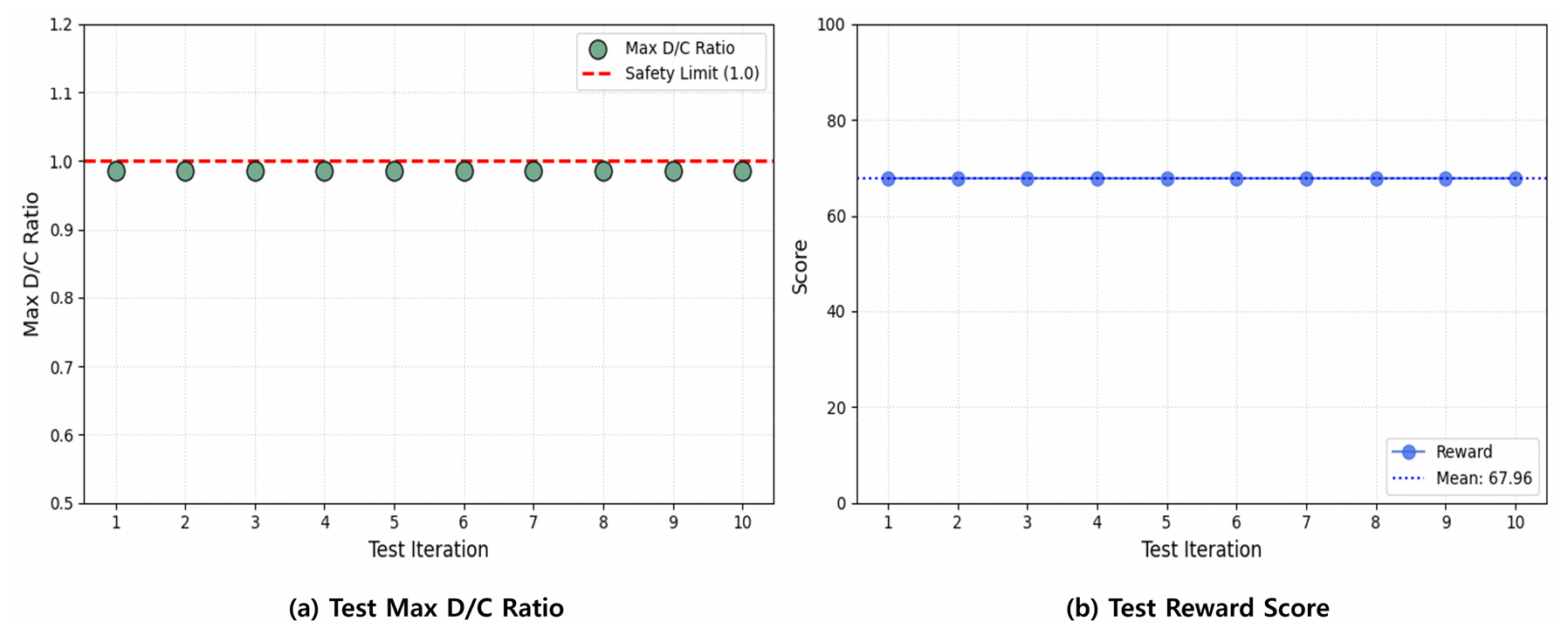
본 연구에서 확인된 높은 수렴 안정성과 에이전트의 견고함은 하중 조건이나 재하 위치가 가변적인 실무 설계 환경에서 모델의 범용적 재사용 가능성을 뒷받침하는 중요한 기술적 근거가 된다. 이는 에이전트가 특정 시나리오에 과적합되지 않고 최적화의 본질적인 메커니즘을 체득했음을 의미한다. 결과적으로 이러한 정책의 유연한 제약 조건 처리 능력은 향후 다양한 하중 시나리오를 포괄하는 설계 시스템으로의 고도화 가능성을 시사한다.
5. 결 론
본 연구에서는 사전 데이터 구축의 한계를 극복하고 구조설계의 경제성과 신뢰성을 동시에 확보하기 위해, 구조 해석 엔진과 강화학습 알고리즘(PPO)을 직접 연동한 지능형 구조 최적화 프레임워크를 제안하였다. 합성보 단면 설계 및 정정 트러스 구조 설계에 이를 적용하여 성능을 검증한 결과, 다음과 같은 결론을 도출하였다.
첫째, 제안된 모델은 사전에 구축된 데이터셋에 의존하지 않고, 에이전트가 해석 엔진과의 실시간 상호작용을 통해 구조물의 역학적 거동을 스스로 파악하였다. 트러스 최적화의 경우 에이전트는 명시적인 제약 조건을 부여받지 않았음에도 불구하고 하중 경로와 구조물의 역학적 대칭성을 자율적으로 학습하여 대칭 단면을 도출하는 지능적 거동을 입증하였다.
둘째, 전통적인 메타휴리스틱 기법인 유전알고리즘(GA)과 비교한 결과, 제안된 강화학습 에이전트는 더 넓고 유연한 기하학적 형상 탐색을 수행하였다. 합성보 설계에서는 보의 춤을 대폭 축소하여 GA 모델 대비 전체 강재 사용량을 추가적으로 절감하였으며, 트러스 설계에서도 GA보다 제약 조건의 한계선(응력비 0.99)에 더욱 정밀하게 접근하여 부재의 잉여 내력을 최소화하는 고도화된 전역 최적해(Global Optimum)를 도출하였다.
셋째, 유전알고리즘(GA) 등 기존의 메타휴리스틱 최적화 방식은 탐색 과정의 무작위성으로 인해 실행 시마다 결과값이 변동되거나 국부 최적해(Local Minima)에 빠지는 치명적인 불안정성을 내포하고 있다. 반면, 본 연구의 강화학습 프레임워크는 학습이 완료된 후 추론 단계에서 결정론적 정책을 통해 해를 산출한다. 10회의 독립적인 반복 테스트 결과, 변동성 없이 동일하고 안전한 최적 설계안을 도출해 내어 결과의 신뢰성을 입증하였다. 이러한 수렴 안정성은 에이전트가 특정 시나리오에 과적합 되지 않고 최적화의 본질적인 메커니즘을 견고하게 학습했음을 의미하며, 이는 향후 가변적인 하중 조건에서도 모델을 범용적으로 재사용할 수 있음을 보인다.
넷째, 본 모델은 보상 함수를 통해 현행 설계기준의 복잡한 비선형 제약 조건들을 엄격하게 준수하면서도 최상의 효율을 달성하였다. 한 번 학습된 모델은 추론 과정에서 신경망의 순전파 연산만을 수행하므로, 막대한 계산 시간이 소요되는 기존 최적화 기법들과 달리 실시간 수준의 빠른 의사결정이 가능하다.
결론적으로 본 연구에서 제안한 강화학습 기반 설계 프레임워크는 기존 탐색 알고리즘의 불안정성과 데이터 의존성을 동시에 해결하였다. 특히 반복 테스트를 통해 검증된 정책의 견고함은 하중 크기나 재하 위치가 변경되는 다양한 설계 환경에서도 전이 학습(Transfer Learning) 등을 통해 모델을 신속하게 재적용할 수 있는 범용적 확장성을 제공한다. 향후 연구에서는 다중 하중 조합 및 설계 조건 하에서의 일반화 성능을 정량적으로 분석함으로써, 실무 설계 환경의 불확실성에 유연하게 대응할 수 있는 구조설계 시스템으로 고도화할 계획이다. 따라서 본 프레임워크는 향후 다양한 하중 시나리오와 복잡한 구조 시스템을 포괄하는 지능형 자율 구조설계(Autonomous Structural Design)의 핵심 엔진으로 활용될 수 있을 것으로 기대된다.
